什么是物种分布模型(SDM),为什么它这么重要?
如果我们做生态学、进化生物学、地理学,或者只是对“物种在哪里出现、未来会去哪”感兴趣,那么一定绕不开一个核心工具:物种分布模型(Species Distribution Model, SDM)。它是连接“生态数据 + 气候环境 + 空间预测”的核心桥梁。
SDM通过建立:
- 物种出现记录(presence data)
- 环境变量(environmental variables)
之间的关系(统计或机器学习关系),来推断物种的“生态位”,并进行空间预测。这不仅帮助我们理解物种的生态需求,还能预测它们在未来气候变化下的潜在分布。
目前常见的SDM方法主要包括3类:
- 传统统计模型,如GLM和GAM,适合线性或简单非线性关系,优点是解释性强,但对复杂关系表达有限。
- 机器学习方法,如随机森林和支持向量机,能捕捉复杂非线性关系,适合大数据,但可能过拟合且解释性较差。其中以MaxEnt(最大熵模型)最为流行,特别适用于仅有物种出现数据的情况。
- 集成模型,通过组合多个模型结果来提高预测稳定性。
1 准备
1.1 安装和加载必要的R包
1.2 物种数据获取与整理
1.2.1 确定目标物种与工作目录
我们以拟南芥(Arabidopsis thaliana)为例。
here("outputs")[1] "D:/Myblog/outputs"sp_target <- "Arabidopsis thaliana"
dir.create(here("outputs", sp_target), showWarnings = FALSE)1.2.2 获取物种分布数据
GBIF(全球生物多样性信息设施)是一个重要的物种分布数据来源。我们将使用 rgbif 包从GBIF获取拟南芥的分布数据。
-
GBIF数据库中,每个物种都有唯一物种识别号。 - 使用该识别号可以统计当前馆藏的有经纬度记录的样本数。
# 获取拟南芥的物种识别号
key <- name_suggest(q = sp_target, rank = "species")$data$key[1]
key[1] 3052436# 统计当前馆藏的有经纬度记录的样本数
occ_count(taxonKey = key, hasCoordinate = T, basisOfRecord = "PRESERVED_SPECIMEN")[1] 13532接下来是核心步骤,从 GBIF 下载 occurrence 数据:
- 可以手动设置国家偏好,默认的是下载全球数据。比如
country = "US"就是下载美国的,"CN"是中国的编号。 - 限制了下载数量为300条,可以按需更改。
- 要求必须带有坐标,且
"PRESERVED_SPECIMEN",必须有馆藏标本记录,这个置信度更高。
tic("GBIF query")
data <- occ_search(
scientificName = sp_target,
# country = "CN", # 可以设置国家偏好
limit = 300, # 下载数量限制
hasCoordinate = TRUE, # 必须带有坐标
basisOfRecord = "PRESERVED_SPECIMEN" # 必须有馆藏
)
toc()GBIF query: 3.42 sec elapsed1.2.3 整理物种数据结构
-
GBIF下载的数据结构比较复杂,我们需要提取出我们关心的部分:即物种明、经纬度和国家。 -
GBIF的数据有很多需要矫正,例如经纬度可能存在错误,或者记录的国家与坐标不匹配等。
1.2.4 物种数据初步可视化
检查数据是否正常。
library(rnaturalearth) # 获取自然地理数据
# 加载世界地图
world_map <- ne_countries(scale = "medium", returnclass = "sf")
site_data <- datasel |> st_as_sf(coords = c("Long", "Lat"), crs = 4326) # 转换为sf对象
# 初步可视化-世界地图 + 物种分布点
ggplot() +
geom_sf(data = world_map, fill = "tan2", color = NA) +
geom_sf(data = site_data, shape = 21, fill = "red", color = "white", size = 3) +
theme_void() +
theme(panel.background = element_rect(fill = "lightblue"))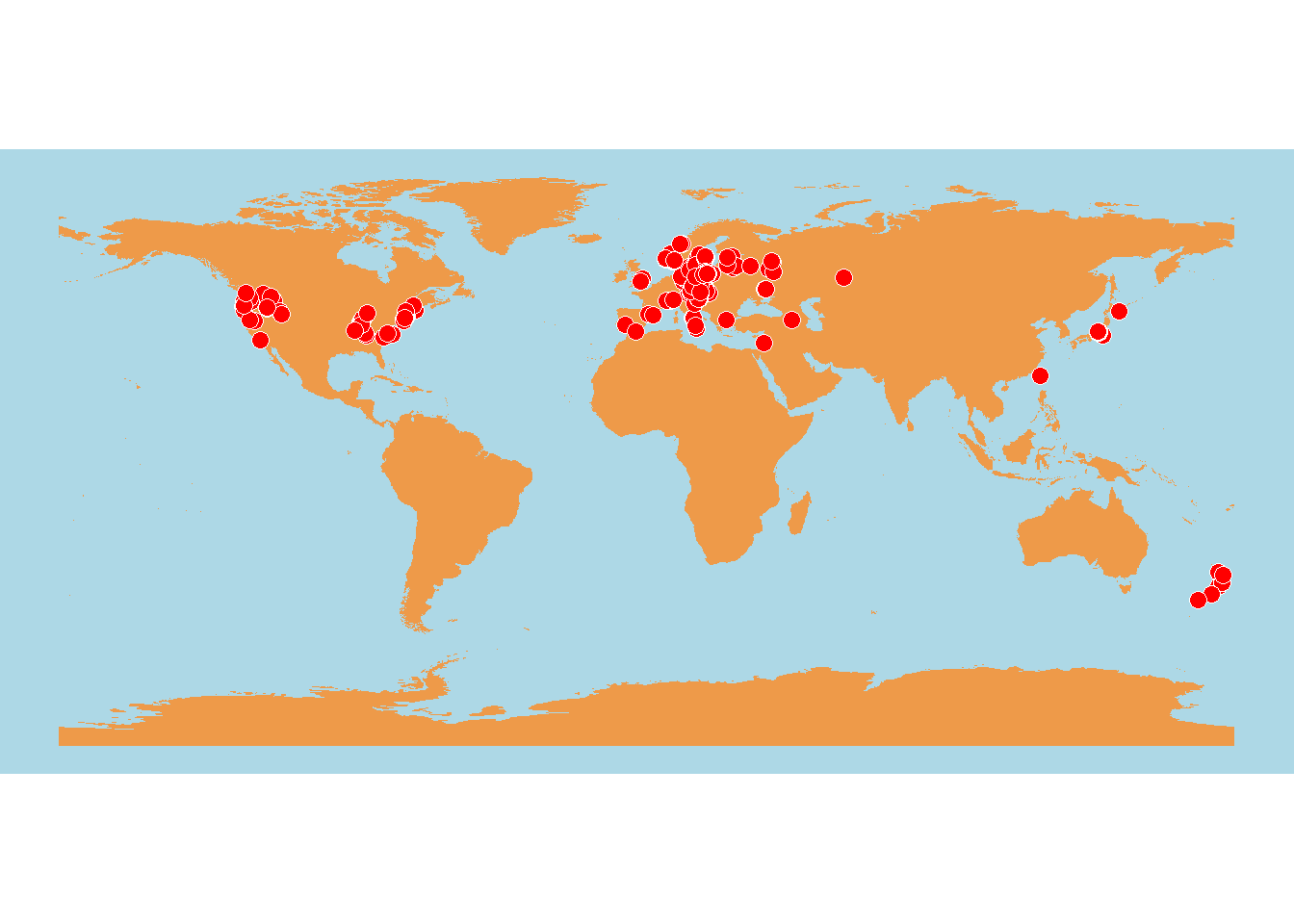
1.2.5 保存处理好的物种数据
dir.create(here("outputs", sp_target), showWarnings = FALSE, recursive = TRUE) # 确保目录存在
datasel |>
select(Long, Lat, everything()) |>
write_csv(here("outputs", sp_target, paste0(sp_target, "-site.csv")))1.3 环境数据获取与整理
拿到物种分布数据后,最关键的步骤就是:为每个点位匹配对应的环境因子。
如果手动在GIS里逐个点击栅格值,几十个点尚可忍受,但面对成百上千条记录,这几乎是灾难。因此,我们需要自动化的方法来提取每个点位的环境数据。
-
读取当前气候栅格:批量加载 WorldClim 的 19 个
Bioclim变量(2.5 分分辨率)。 -
提取点位气候值:一句
raster::extract()完成所有物种记录点的环境匹配。 -
处理未来气候情景:读取
ACCESS‑CM2模式、SSP5‑8.5路径、2061‑2080年数据。 -
清洗缺失值:剔除经纬度错误导致的
NA记录,保证数据质量。 -
导出整洁表格:直接用于
MaxEnt物种分布模型。
1.3.1 读取当前气候栅格数据
数据来自 WorldClim,该网站继承了当前及未来的生物气候数据。我们使用 terra 包来加载这些栅格数据。
具体下载步骤可参看R语言做物种分布模型二:根据经纬度进行气候数据提取。
PC网络都不好用,可以用手机迅雷。
[1] "bio_1.tif" "bio_10.tif" "bio_11.tif" "bio_12.tif" "bio_13.tif"
[6] "bio_14.tif" "bio_15.tif" "bio_16.tif" "bio_17.tif" "bio_18.tif"
[11] "bio_19.tif" "bio_2.tif" "bio_3.tif" "bio_4.tif" "bio_5.tif"
[16] "bio_6.tif" "bio_7.tif" "bio_8.tif" "bio_9.tif" 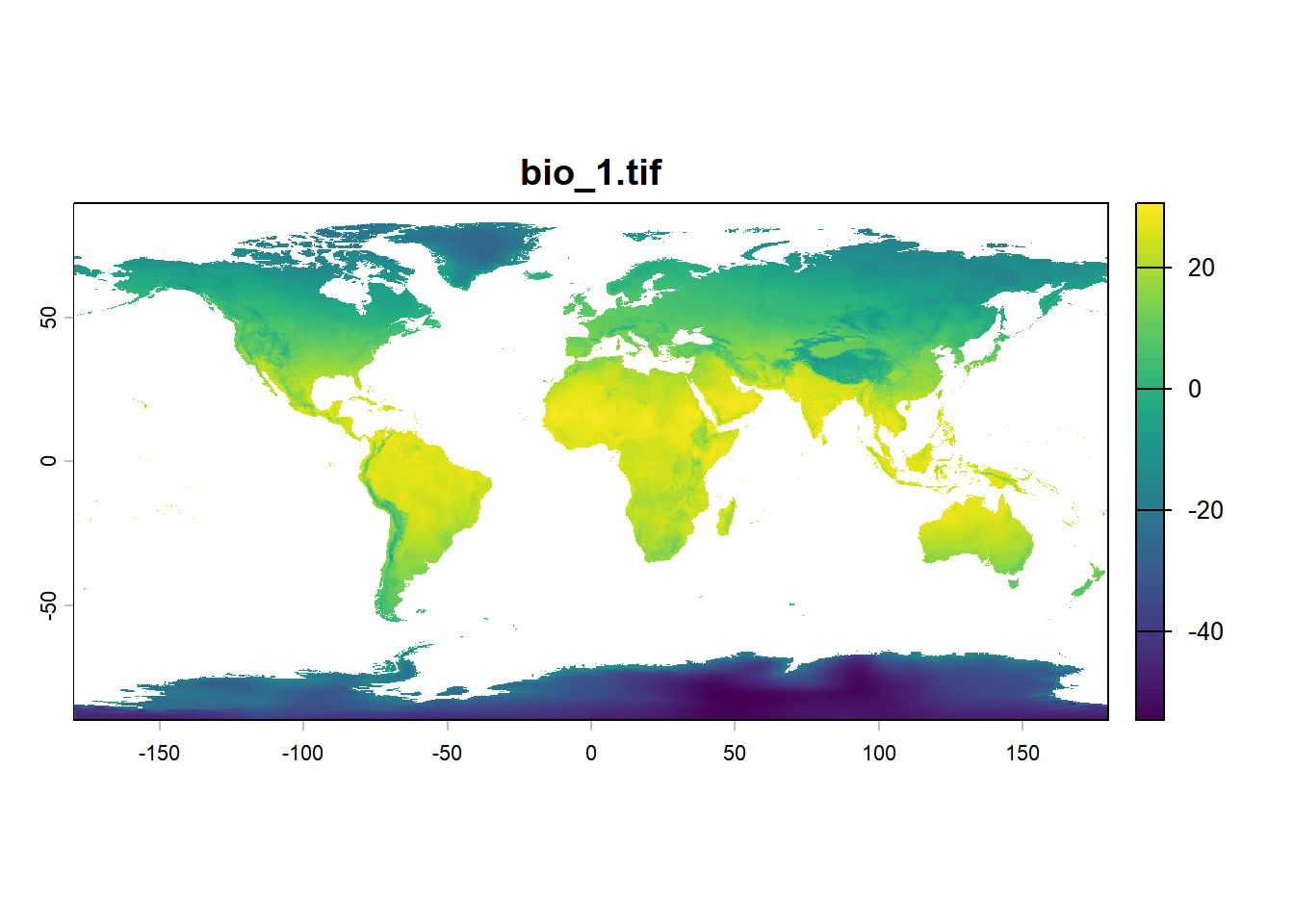
# 从所有的记录中提取19个环境因子对应值
data_clim <- terra::extract(
bioclim,
datasel |> select(Long, Lat) |> as.matrix(), # 提取经纬度列并转换为矩阵格式
# ID = FALSE # 不需要返回ID列
)
datasel_clim <- datasel |>
bind_cols(data_clim) |> # 将提取的环境数据与物种记录合并
drop_na() # 删除包含NA的行
# 这个表格现在同时包含了物种记录和环境数据head(datasel_clim)
datasel_clim |> write_tsv(here("outputs", sp_target, "current-climate.tsv"))1.3.2 提取未来气候数据
[1] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_1"
[2] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_2"
[3] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_3"
[4] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_4"
[5] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_5"
[6] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_6"
[7] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_7"
[8] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_8"
[9] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_9"
[10] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_10"
[11] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_11"
[12] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_12"
[13] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_13"
[14] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_14"
[15] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_15"
[16] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_16"
[17] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_17"
[18] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_18"
[19] "wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2021-2040_19"names(future_clim) <- gsub(
'wc2.1_2.5m_bioc_ACCESS-CM2_ssp585_2061-2080',
'bio',
names(future_clim)
)
# 从所有的记录中提取19个环境因子对应值
future_clim_extr <- terra::extract(
future_clim,
datasel |> select(Long, Lat) |> as.matrix()
)
datasel_clim_future <- datasel |> bind_cols(future_clim_extr) |> drop_na() # 删除包含NA的行
datasel_clim_future <- na.omit(datasel_clim_future)
datasel_clim |> write_tsv(here("outputs", sp_target, "futrue-climate.tsv"))