使用ggplot2对地震数据进行分析。我国使用的震级标准是国际上的里氏分级表,一共 9 个等级。小于 3 级的地震不易察觉。4.5 级及以下的地震一般不会造成破坏。大于 4.5 级而小于 6 级的地震可以造成破坏,具体破坏情况还与震源深度、震中距等多种因素有关。震级每相差 1.0 级,能量相差大约 30 倍,震级相差 0.1 级,释放的能量平均相差 1.4 倍。一个 6 级地震释放的能量相当于美国投掷在日本广岛的原子弹所具有的能量。一个 7 级地震释放的能量相当于 30 颗这样的原子弹,而一个 8 级地震释放的能量相当于 900 颗这样的原子弹。(https://www.cgs.gov.cn/)
- 1976 年河北唐山地震震级为 7.6 级。
- 2008 年四川汶川地震震级为 8.0 级。
- 2013 年四川雅安地震震级为 7.0 级。
- 2021 年青海玛多地震震级为 7.4 级。
从上面四个危害严重地震的时间间隔来看,似乎地震发生的频率越来越高了?当然不能这样草草的下结论。
1 1973-2010年全球地震变化
1.1 数据准备
数据集来自MSG包,是《现代图形统计》的配套包,本书我正好持有,学到了很多。着xiangyun没有使用tidy的思想,我则尝试使用。
Rows: 4,999
Columns: 9
$ Cat <fct> PDE, PDE, PDE, PDE, PDE, PDE, PDE, PDE, PDE, PDE, PDE, PDE, …
$ year <fct> 1973, 1973, 1973, 1973, 1973, 1973, 1973, 1973, 1973, 1973, …
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, …
$ day <int> 1, 5, 6, 10, 15, 18, 22, 23, 27, 30, 31, 1, 6, 8, 14, 24, 25…
$ time <dbl> 114237.5, 135429.1, 155241.9, 113227.4, 90258.3, 92814.1, 37…
$ lat <dbl> -35.51, -39.00, -14.66, -11.10, 27.08, -6.87, 18.60, -12.09,…
$ long <dbl> -16.21, 175.23, 166.38, 162.28, 140.10, 149.99, -104.97, 166…
$ dep <int> 33, 150, 36, 32, 477, 43, 33, 97, 55, 43, 498, 229, 33, 33, …
$ magnitude <dbl> 6.0, 6.2, 6.1, 6.0, 6.0, 6.8, 6.2, 6.3, 6.0, 7.5, 6.3, 6.7, …数据共有4999行9列,分别是 Cat 、年份 year、月份 month、日 day、时间 time、纬度 lat、经度 long、震深 dep 和震级 magnitude。
1.2 震次趋势(年度)
先看看每年地震变化的趋势,如 图 1 所示。
quake6 %>%
group_by(year) %>%
summarise(time = n()) %>%
ggplot(aes(x = year, y = time)) +
geom_point() +
geom_line() +
theme_classic() +
theme(panel.grid.major.y = element_line(color = "grey90")) +
labs(x = "年份", y = "地震次数")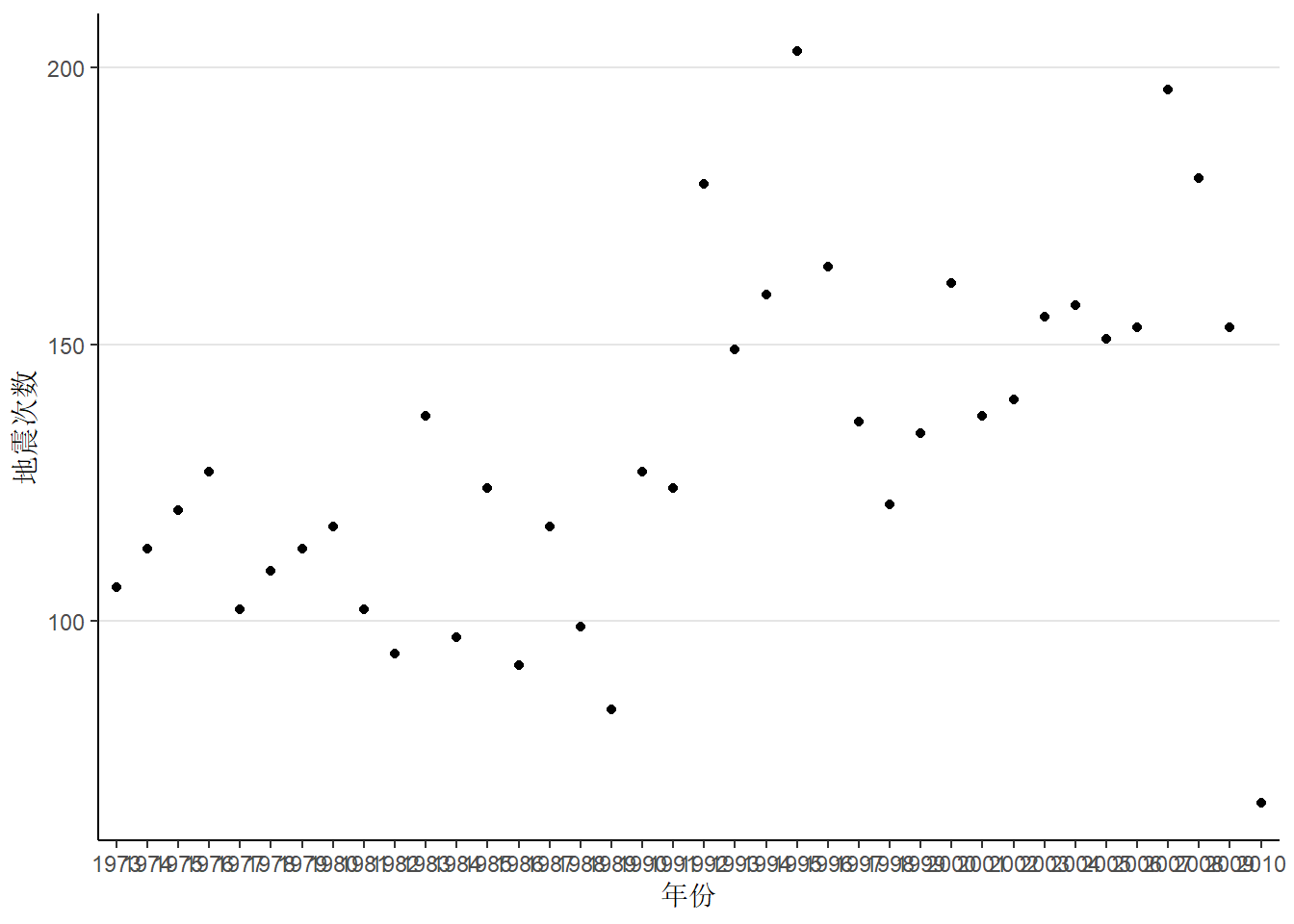
1.3 地震分布
1.3.1 总体情况
range(quake6$magnitude)[1] 6 9数据中记录的震级为6~9级。
ggplot(quake6, aes(x = magnitude)) +
geom_histogram(bins = 31, color = "gray40", fill = "gray90") +
geom_freqpoly(stat = "count") +
theme_minimal() +
labs(x = "震级", y = "次数")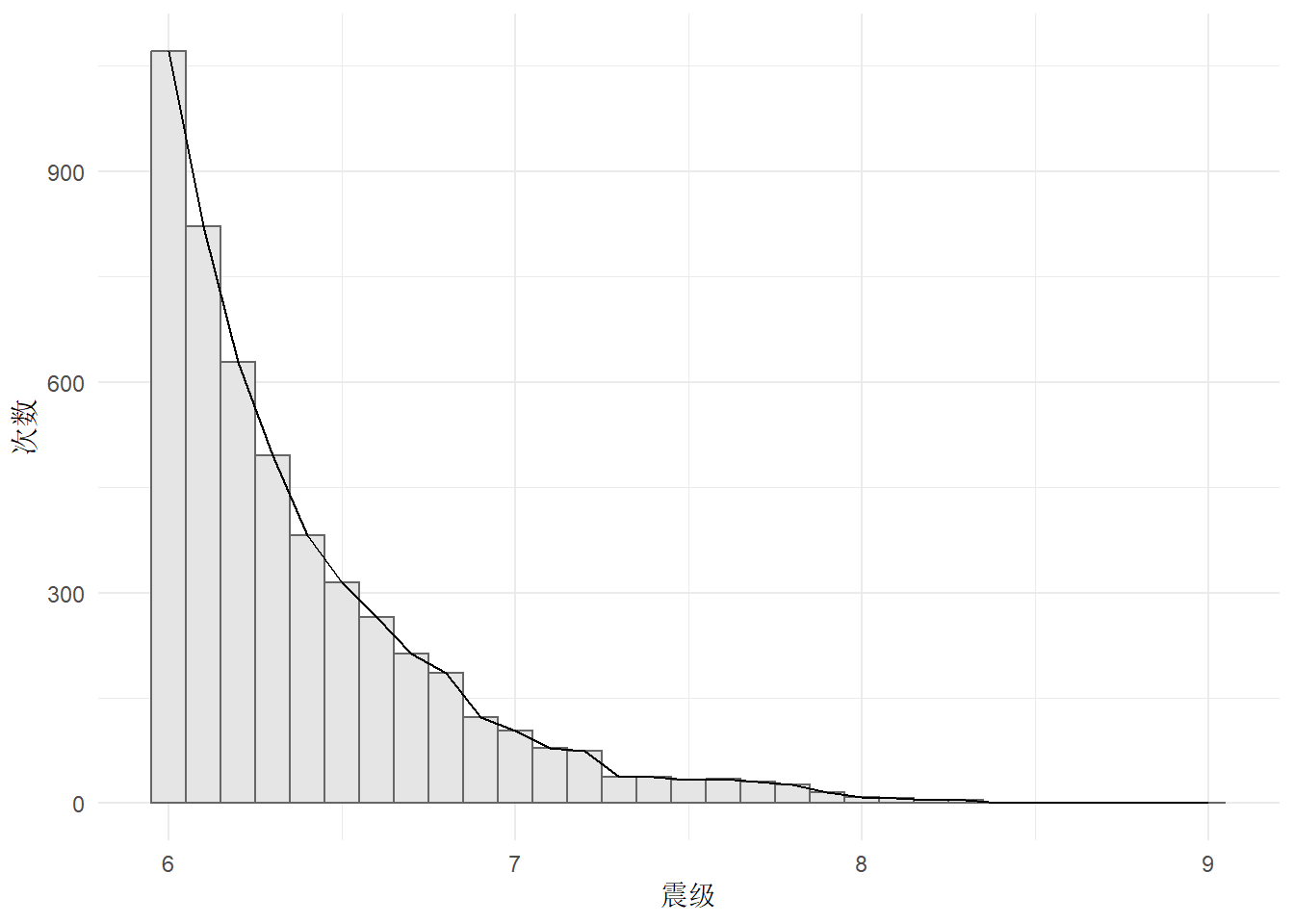
震级的总体分布情况有点像指数分布。
1.3.2 按年分组
1.3.2.1 抖动图
quake6数据集不算大,可以用 ggbeeswarm 包将所有点绘制出来,添加抖动后,可以防止一定程度的覆盖重合。散点的疏密体现数据的分布,相比于直方图,附加好处是直观地展示原始信息,特别是位于分布尾部的数据。
library(ggbeeswarm)
ggplot(
quake6,
aes(x = as.factor(year), y = magnitude, colour = as.factor(year))
) +
geom_quasirandom(groupOnX = TRUE) +
coord_flip() +
geom_jitter() +
theme_minimal() +
theme(legend.position = "none") +
labs(y = "震级", x = "年份")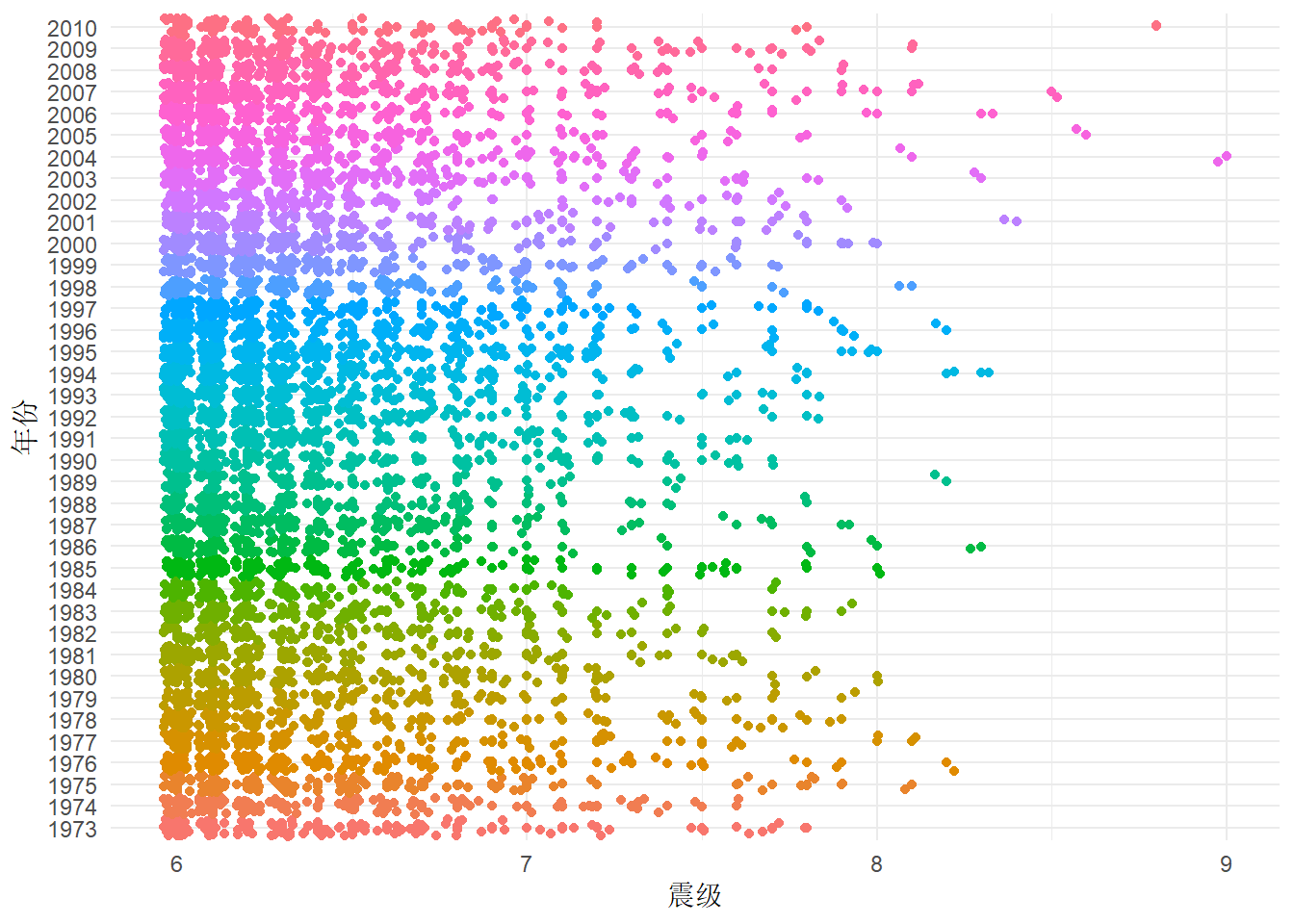
从图中看,震级之间有明显的间隔,是不连续的。
1.3.2.2 岭线图
岭线图也可以来展示数据的分布变化,相邻的年份分布可以清晰的对比,多个年份的分布也可以看清趋势。
library(ggridges)
ggplot(
quake6,
aes(
x = magnitude,
y = year,
height = after_stat(density)
)
) +
geom_ridgeline(stat = "density") +
theme_ridges() +
labs(x = "震级", y = "年份")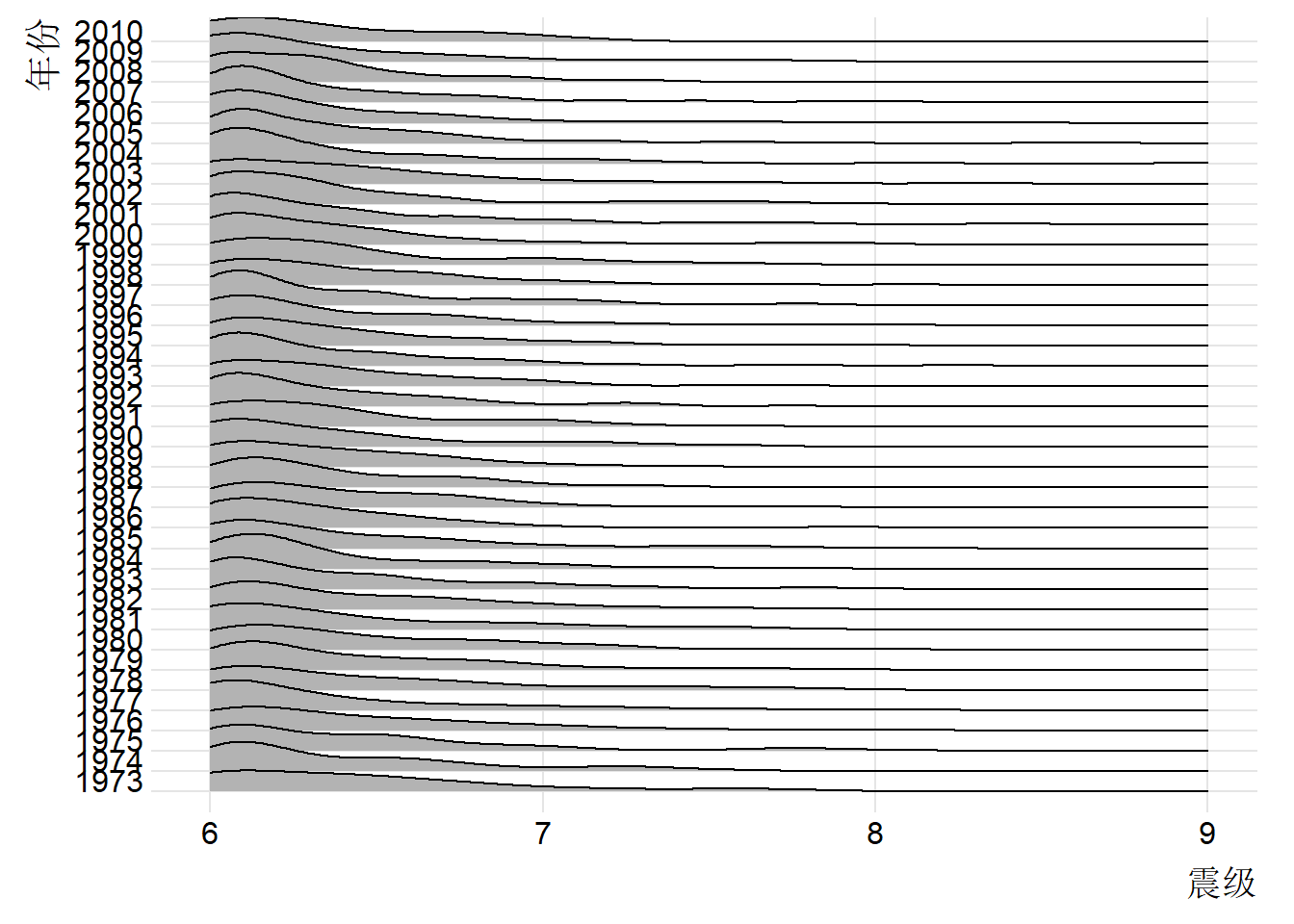
1.3.2.3 箱线图
ggplot(quake6, aes(x = magnitude, y = year)) +
geom_boxplot() +
theme_minimal() +
labs(x = "震级", y = "年份")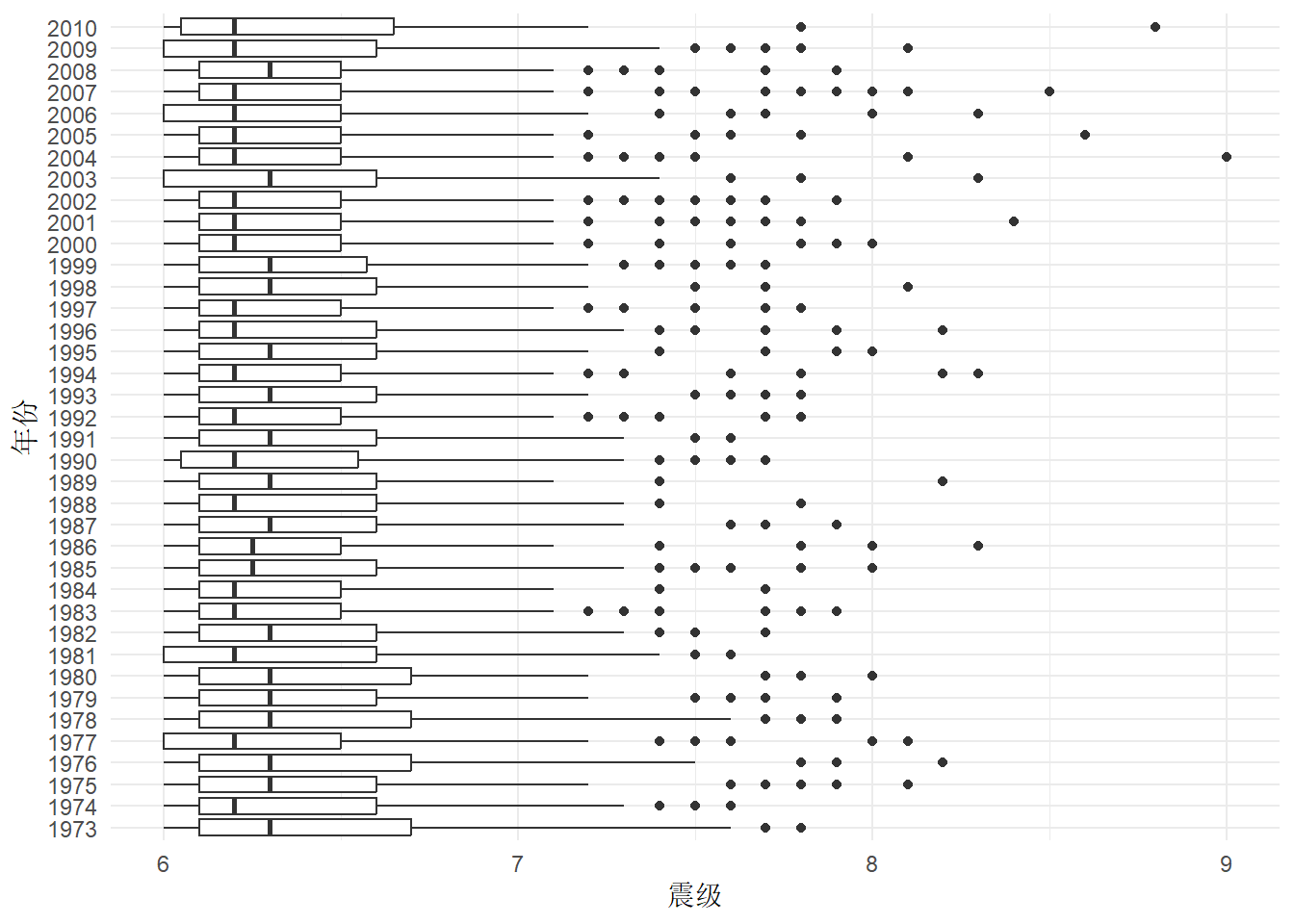
箱线图将 5 个分位点和离群点画出来了,就地震来说,小地震往往破坏力不大,大地震才是关注的重点,也就是图中那些离群点。
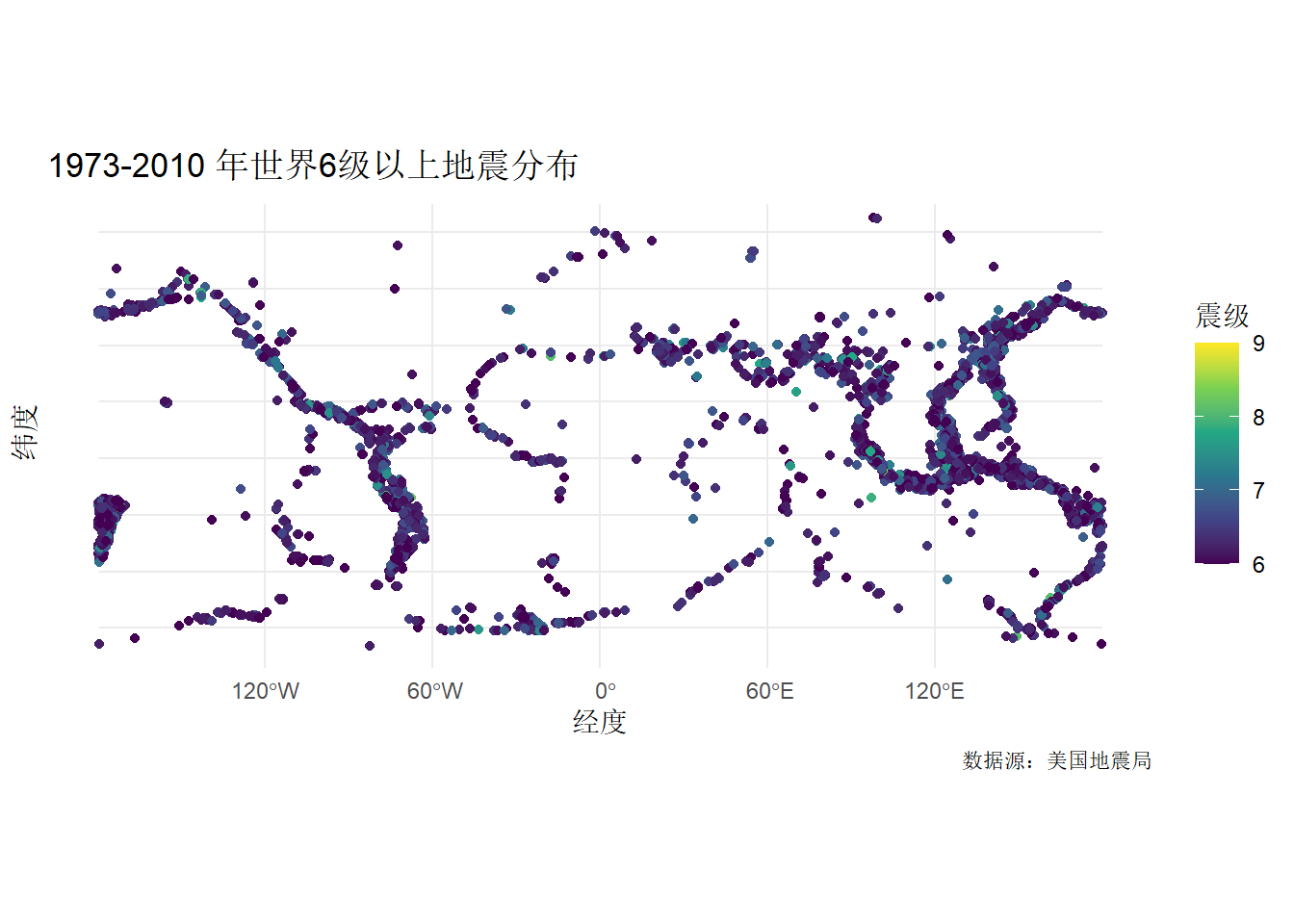
1.3.3 按空间分-未来尝试加入世界地图的底图
这个就需要用到空间作图的sf包了。
library(sf)
# 将数据转换为sf类型
quake6_sf <- st_as_sf(quake6, coords = c("long", "lat"), crs = 4326)
# 绘图
ggplot(quake6_sf, aes(color = magnitude), cex = 0.1) +
geom_sf() +
scale_color_viridis_c() +
theme_minimal() +
labs(
x = "经度",
y = "纬度",
color = "震级",
title = "1973-2010 年世界6级以上地震分布",
caption = "数据源:美国地震局"
)
2 2012-2022年中国地震变化
x <- read.delim("d:/Myblog/datas/quakes_20220812.xls", header = FALSE)
x[4:25, ] [1] "<Table>"
[2] "<Column ss:Index=1 ss:AutoFitWidth=0 ss:Width=110/>"
[3] "<Row>"
[4] "<Cell><Data ss:Type=String>发震时刻</Data></Cell>"
[5] "<Cell><Data ss:Type=String>震级(M)</Data></Cell>"
[6] "<Cell><Data ss:Type=String>纬度(°)</Data></Cell>"
[7] "<Cell><Data ss:Type=String>经度(°)</Data></Cell>"
[8] "<Cell><Data ss:Type=String>深度(千米)</Data></Cell>"
[9] "<Cell><Data ss:Type=String>参考位置</Data></Cell>"
[10] "</Row>"
[11] "<Row>"
[12] "<Cell><Data ss:Type=String>2022-08-11 23:58:52</Data></Cell>"
[13] "<Cell><Data ss:Type=Number>3.0</Data></Cell>"
[14] "<Cell><Data ss:Type=Number>27.23</Data></Cell>"
[15] "<Cell><Data ss:Type=Number>103.75</Data></Cell>"
[16] "<Cell><Data ss:Type=Number>15</Data></Cell>"
[17] "<Cell><Data ss:Type=String>云南昭通市昭阳区</Data></Cell>"
[18] "</Row>"
[19] "<Row>"
[20] "<Cell><Data ss:Type=String>2022-08-11 15:47:07</Data></Cell>"
[21] "<Cell><Data ss:Type=Number>2.5</Data></Cell>"
[22] "<Cell><Data ss:Type=Number>36.36</Data></Cell>" x是一个超长的字符串,信息都隐藏在cell中。
# 准备字符串提取的函数,从一个给定字符串向量中,按照匹配模式提取一部分
st_extract <- function(text, pattern, ...) {
regmatches(text, gregexpr(pattern, text, ...))
}
# 从字符串向量中过滤出含表头、发震时刻、震级 (M)、纬度(°)、经度(°)、深度(千米)
# 和参考位置等字段信息的子字符串向量。
x_str <- st_extract(
text = x$V1,
pattern = "<Cell><Data ss:Type=(String|Number)>(.*?)</Data></Cell>"
)
x_str <- unlist(x_str)
head(x_str, 20) [1] "<Cell><Data ss:Type=String>发震时刻</Data></Cell>"
[2] "<Cell><Data ss:Type=String>震级(M)</Data></Cell>"
[3] "<Cell><Data ss:Type=String>纬度(°)</Data></Cell>"
[4] "<Cell><Data ss:Type=String>经度(°)</Data></Cell>"
[5] "<Cell><Data ss:Type=String>深度(千米)</Data></Cell>"
[6] "<Cell><Data ss:Type=String>参考位置</Data></Cell>"
[7] "<Cell><Data ss:Type=String>2022-08-11 23:58:52</Data></Cell>"
[8] "<Cell><Data ss:Type=Number>3.0</Data></Cell>"
[9] "<Cell><Data ss:Type=Number>27.23</Data></Cell>"
[10] "<Cell><Data ss:Type=Number>103.75</Data></Cell>"
[11] "<Cell><Data ss:Type=Number>15</Data></Cell>"
[12] "<Cell><Data ss:Type=String>云南昭通市昭阳区</Data></Cell>"
[13] "<Cell><Data ss:Type=String>2022-08-11 15:47:07</Data></Cell>"
[14] "<Cell><Data ss:Type=Number>2.5</Data></Cell>"
[15] "<Cell><Data ss:Type=Number>36.36</Data></Cell>"
[16] "<Cell><Data ss:Type=Number>114.37</Data></Cell>"
[17] "<Cell><Data ss:Type=Number>11</Data></Cell>"
[18] "<Cell><Data ss:Type=String>河北邯郸市磁县</Data></Cell>"
[19] "<Cell><Data ss:Type=String>2022-08-11 11:59:45</Data></Cell>"
[20] "<Cell><Data ss:Type=Number>3.9</Data></Cell>" [1] "发震时刻" "震级(M)" "纬度(°)"
[4] "经度(°)" "深度(千米)" "参考位置"
[7] "2022-08-11 23:58:52" "3.0" "27.23"
[10] "103.75" "15" "云南昭通市昭阳区"
[13] "2022-08-11 15:47:07" "2.5" "36.36"
[16] "114.37" "11" "河北邯郸市磁县"
[19] "2022-08-11 11:59:45" "3.9" 可以说,这种办法简直是把 xls 文件给砸碎了,万幸地是数据文件还可以被当作 XML 文件读取,因此只要 xls 文件坏得还不彻底,这办法总是可以用的。
那么接下来就要拼起来,拼成一个 matrix,每一行记录包含 6 个字段。 字符串向量 x_str_tidy 开头 6 个元素是表头,余下的 x_str_tidy[-c(1:6)] 是观测值,长度为 62646,分成 6 列,一共 10441 行。
发震时刻 震级(M) 纬度(°) 经度(°) 深度(千米)
1 "2022-08-11 23:58:52" "3.0" "27.23" "103.75" "15"
2 "2022-08-11 15:47:07" "2.5" "36.36" "114.37" "11"
3 "2022-08-11 11:59:45" "3.9" "40.15" "77.74" "14"
4 "2022-08-11 09:14:13" "3.7" "40.88" "78.12" "10"
5 "2022-08-11 01:48:16" "3.1" "32.85" "83.44" "10"
6 "2022-08-10 22:41:55" "3.1" "36.04" "78.26" "100"
参考位置
1 "云南昭通市昭阳区"
2 "河北邯郸市磁县"
3 "新疆克孜勒苏州阿图什市"
4 "新疆克孜勒苏州阿合奇县"
5 "西藏阿里地区改则县"
6 "新疆和田地区皮山县" # A tibble: 6 × 6
发震时刻 `震级(M)` `纬度(°)` `经度(°)` `深度(千米)` 参考位置
<chr> <chr> <chr> <chr> <chr> <chr>
1 2022-08-11 23:58:52 3.0 27.23 103.75 15 云南昭通市昭阳区……
2 2022-08-11 15:47:07 2.5 36.36 114.37 11 河北邯郸市磁县
3 2022-08-11 11:59:45 3.9 40.15 77.74 14 新疆克孜勒苏州阿图什市……
4 2022-08-11 09:14:13 3.7 40.88 78.12 10 新疆克孜勒苏州阿合奇县……
5 2022-08-11 01:48:16 3.1 32.85 83.44 10 西藏阿里地区改则县……
6 2022-08-10 22:41:55 3.1 36.04 78.26 100 新疆和田地区皮山县……\(a = 1\)
我们需要进一步对dat进行处理,将每列的数据类型进行变更,如发震时刻列应该是日期类型。
library(lubridate)
dat <- dat %>%
mutate(
发震时刻 = as_datetime(发震时刻, tz = "UTC"),
across(2:5, as.numeric)
) %>%
set_names("发震时刻", "震级", "纬度", "经度", "深度", "参考位置") %>%
mutate(
日期 = format(发震时刻, format = "%Y-%m-%d", tz = "UTC"),
年份 = format(发震时刻, "%Y", tz = "UTC"),
月份 = format(发震时刻, "%m", tz = "UTC"),
时段 = format(发震时刻, "%H", tz = "UTC")
)
dat# A tibble: 10,441 × 10
发震时刻 震级 纬度 经度 深度 参考位置 日期 年份 月份 时段
<dttm> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <chr>
1 2022-08-11 23:58:52 3 27.2 104. 15 云南昭通市昭阳区… 2022… 2022 08 23
2 2022-08-11 15:47:07 2.5 36.4 114. 11 河北邯郸市磁县…… 2022… 2022 08 15
3 2022-08-11 11:59:45 3.9 40.2 77.7 14 新疆克孜勒苏州阿… 2022… 2022 08 11
4 2022-08-11 09:14:13 3.7 40.9 78.1 10 新疆克孜勒苏州阿… 2022… 2022 08 09
5 2022-08-11 01:48:16 3.1 32.8 83.4 10 西藏阿里地区改则… 2022… 2022 08 01
6 2022-08-10 22:41:55 3.1 36.0 78.3 100 新疆和田地区皮山… 2022… 2022 08 22
7 2022-08-10 02:41:20 3 41.9 80.8 18 新疆阿克苏地区温… 2022… 2022 08 02
8 2022-08-09 20:59:42 5.7 -6.9 130. 160 印尼班达海…… 2022… 2022 08 20
9 2022-08-08 13:37:19 5.6 -5.5 152. 60 新不列颠岛地区…… 2022… 2022 08 13
10 2022-08-08 11:00:35 3.7 40.9 78.1 10 新疆克孜勒苏州阿… 2022… 2022 08 11
# ℹ 10,431 more rows2.1 数据探索
那么,我国的地震是不是越来越频繁了呢?
2.1.1 震次分布(棋盘图)
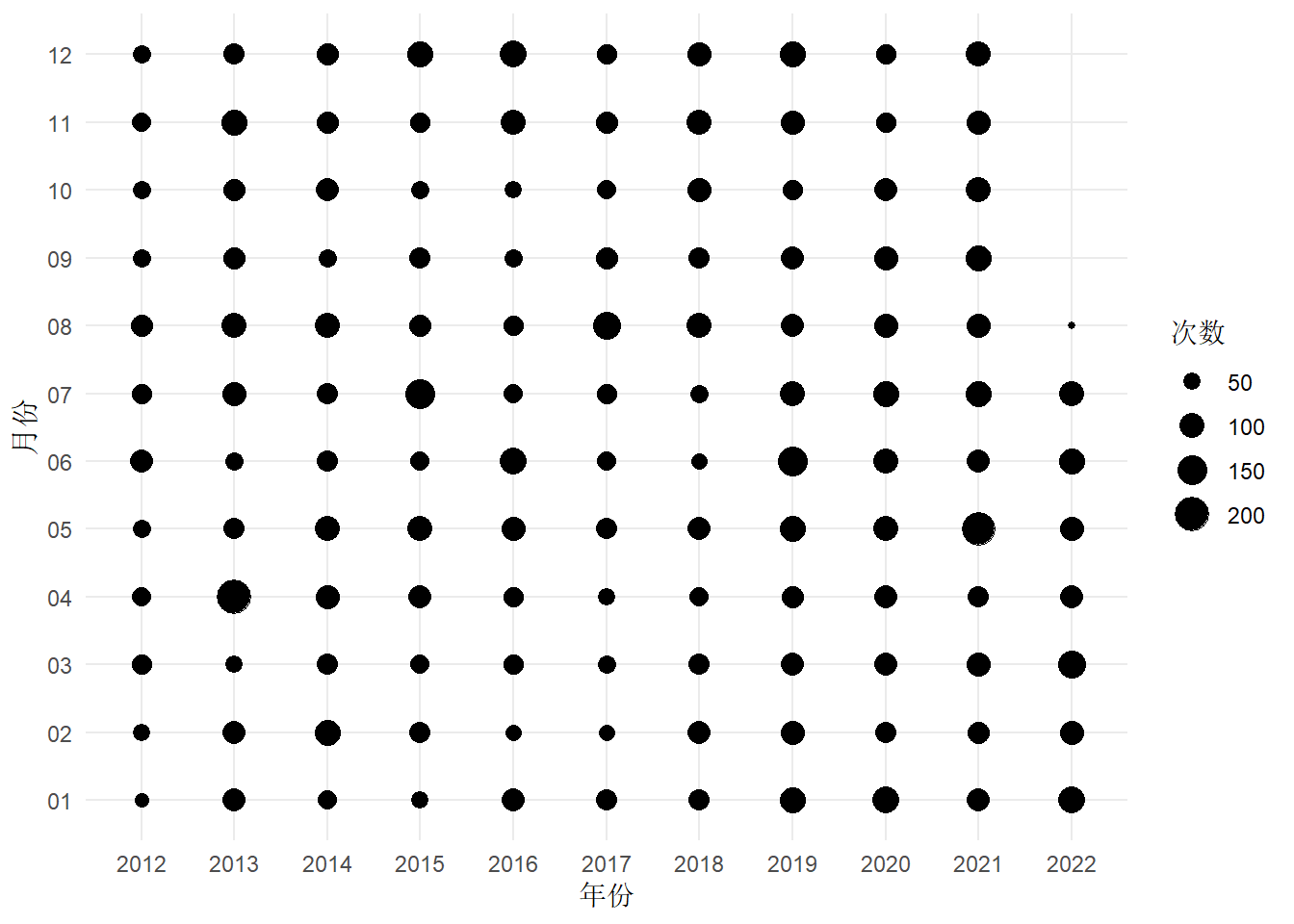
初步看,地震次数有明显增加的趋势,那是不是说地震发生越来越频繁了呢?未必,根据中国地震局发布的新闻公告,地震监测预报预警能力持续提升,还有可能是之前一些小震级、远距离的地震活动没有监测出来。那么,去掉 4.5 级及以下的小地震,相当于减少监测能力的影响,统计大一些的地震数量的变化,应该能说明一些问题。
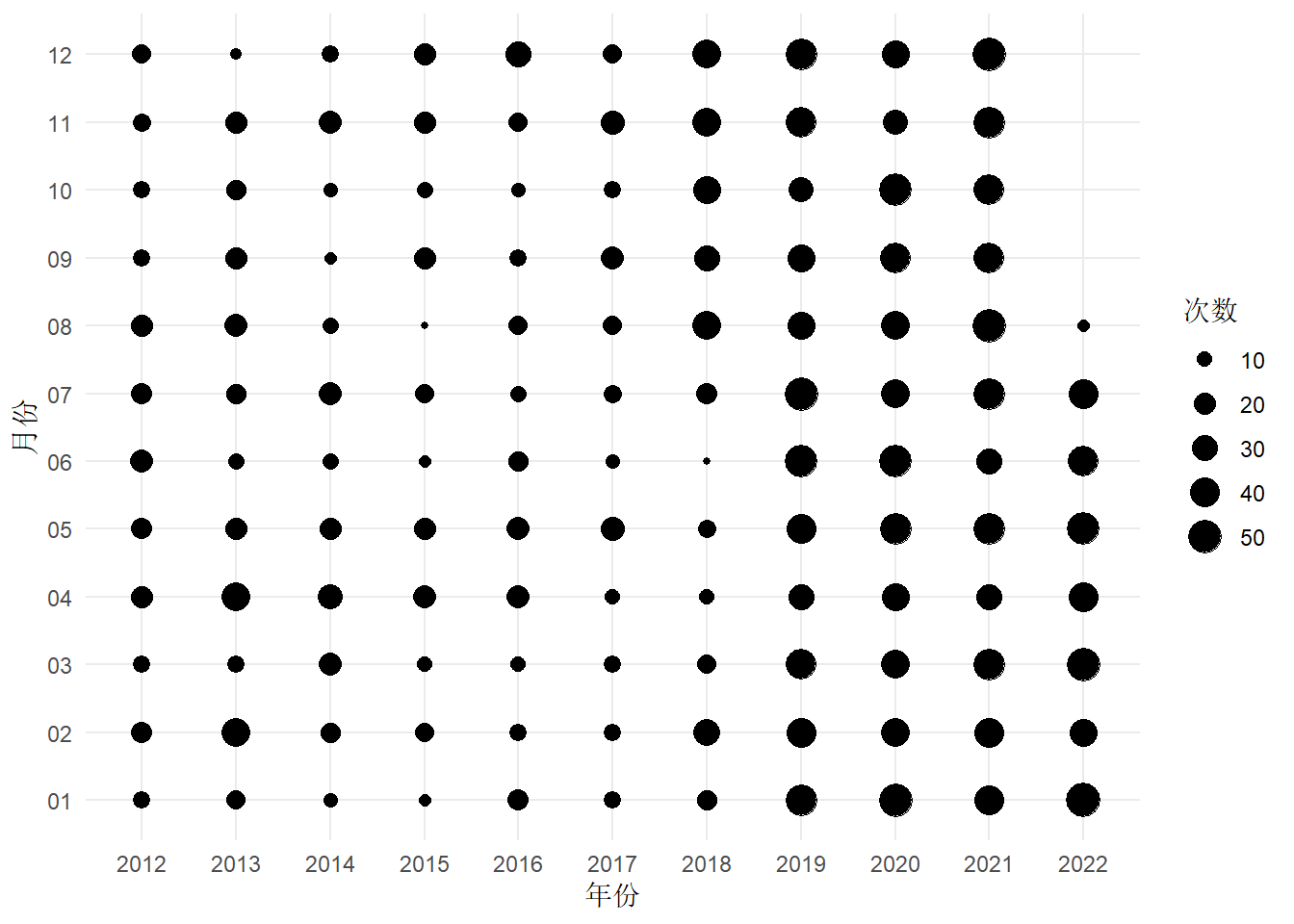
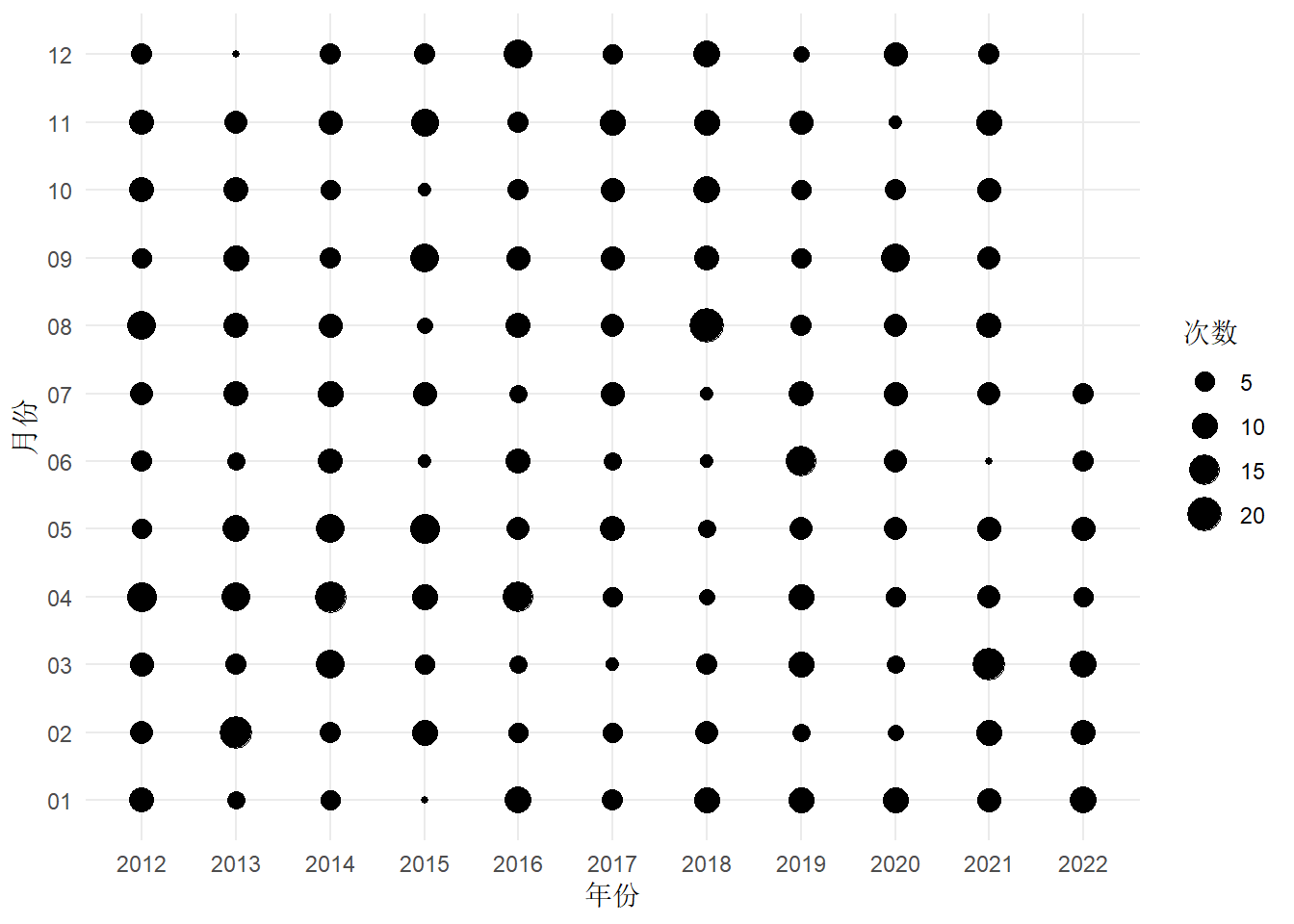
中国地震台网发布的地震活动数据,除了中国境内,还有境外的,而且境外的多半是一些大地震。地震监测相当于空间上不均匀的震级采样,导致大地震貌似变多了。如果将震级大于等于 6 级的筛选出来,结果就不一样了,见下图。
2.1.2 震级分布(直方图)
ggplot(
dat,
aes(
x = 震级,
y = after_stat(count),
fill = 年份
)
) +
geom_histogram(binwidth = 0.2) +
theme_minimal() +
labs(y = "地震次数")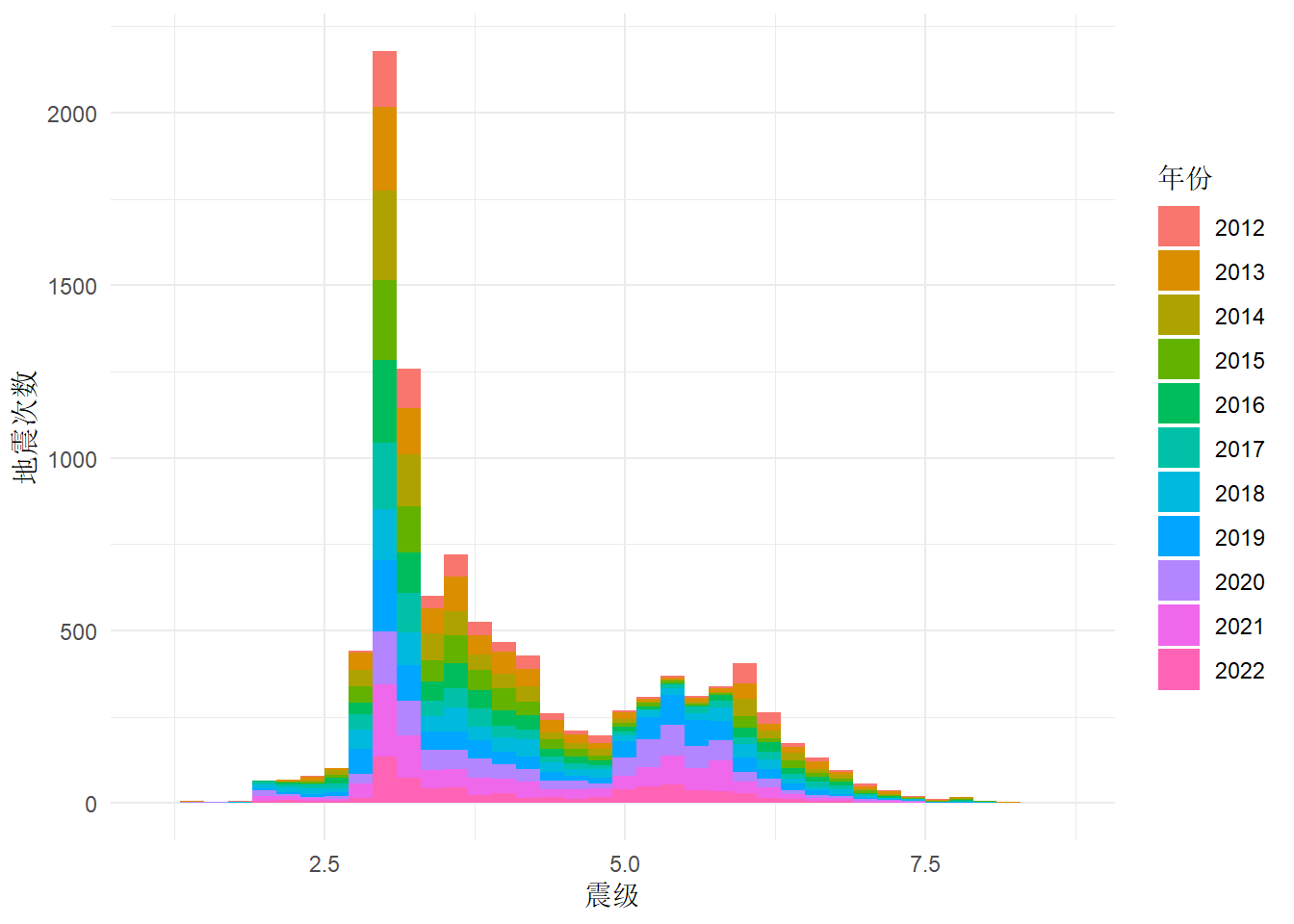
2.1.3 震级分布(抖动图)
ggplot(dat, aes(x = 年份, y = 震级, color = 年份)) +
geom_quasirandom(groupOnX = TRUE) + # 抖动以减少过度绘制
coord_flip() +
geom_jitter() +
theme_minimal()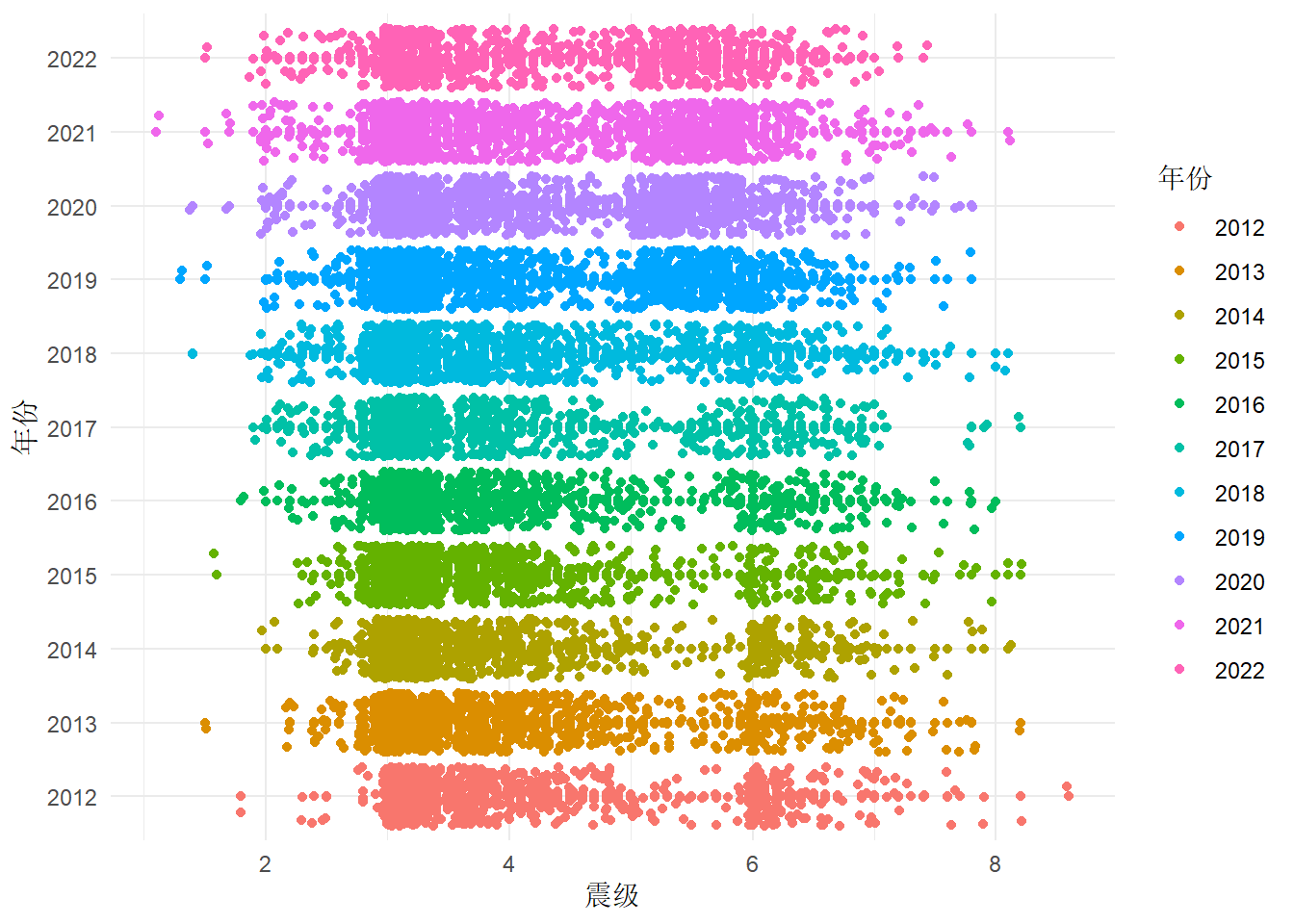
抖动图在散点图的基础上添加随机扰动,其疏密度变化变化能体现震级的分布。
2.1.4 震级分布(岭线图)
ggplot(
dat %>% filter(震级 > 4.5),
aes(x = 震级, y = 年份, fill = 年份)
) +
geom_density_ridges(show.legend = FALSE) +
theme_ridges()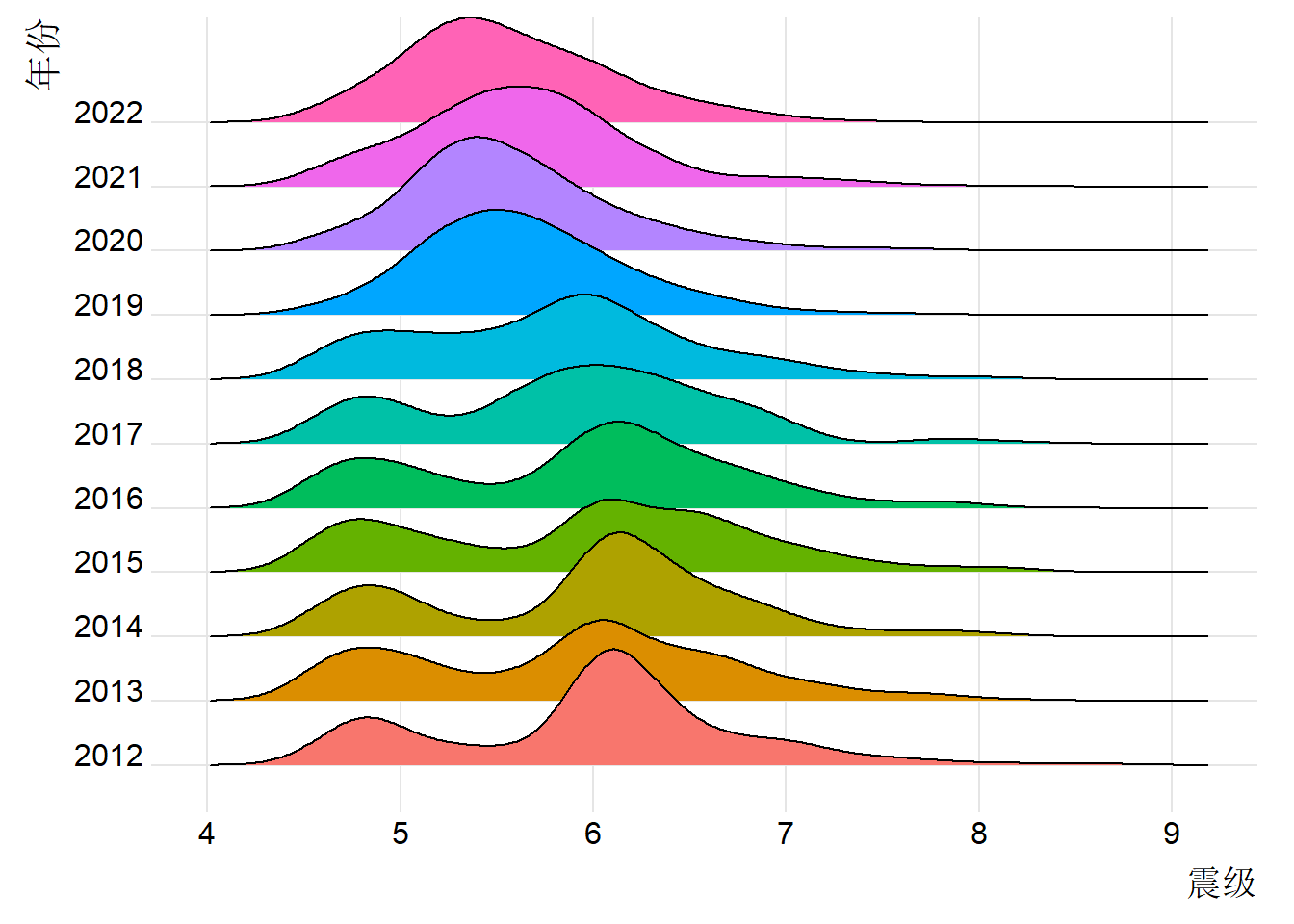
抖动图适用于数据点不太多的情况。如果遇到数据非常多(比如超过10个),仅凭抖动图就不能看出其疏密度了,使用 图 12 这类的岭线图或直方图更合适。
2.2 数据分析
2.2.1 震级的空间分布
library(sf)
dat_sf <- st_as_sf(dat, coords = c("经度", "纬度"), crs = 4326)
ggplot() +
geom_sf(data = dat_sf, aes(color = 震级), cex = 0.1) +
scale_color_viridis_c() +
theme_minimal() +
labs(
title = "2012-04-26 至 2022-08-12 的地震分布",
caption = "数据源:中国地震台网"
)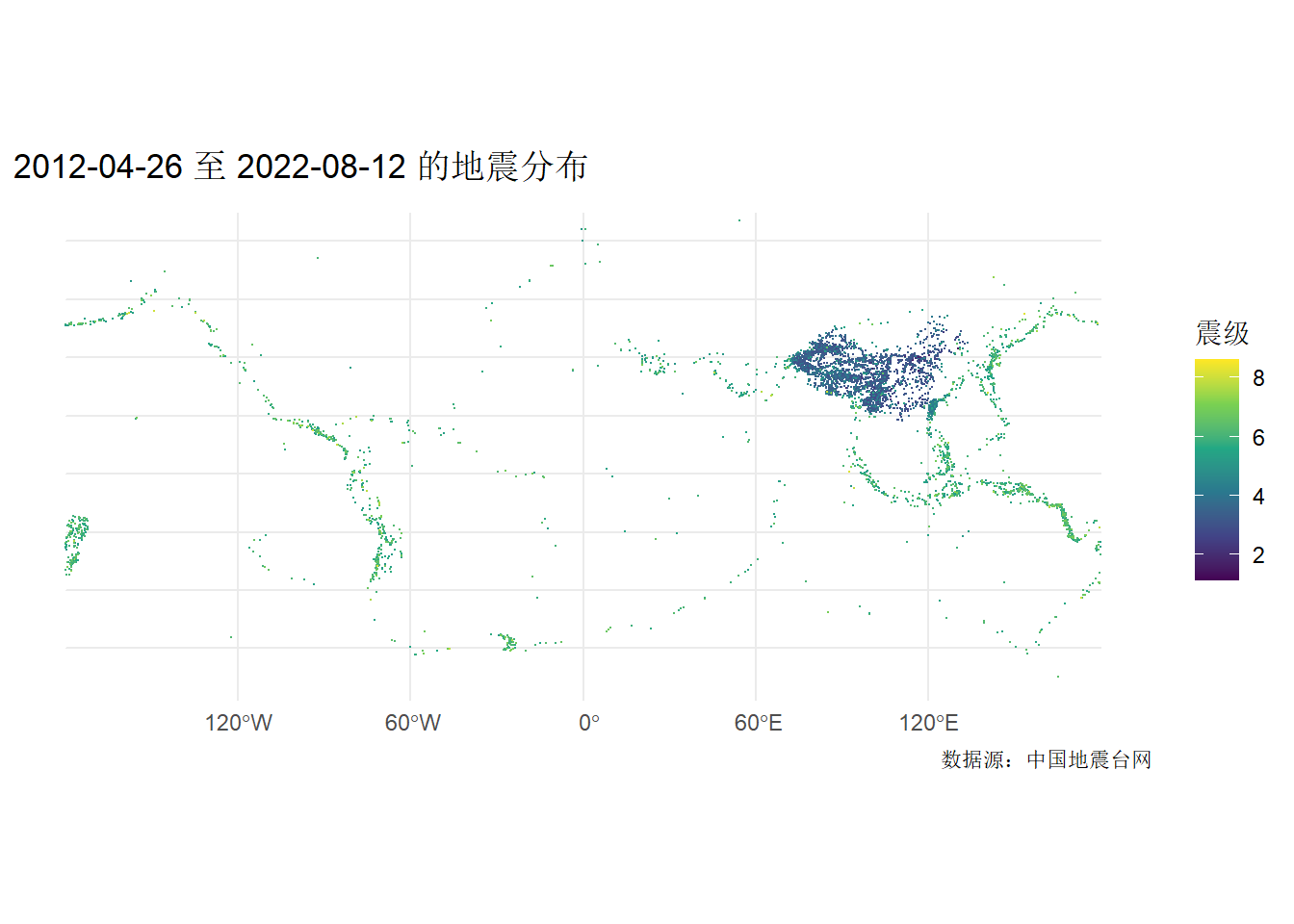
我们重点关注中国的地震(依旧关注震级大于4.5的)。这里需要利用经纬度范围,将我国及周边地区”分割”出来。
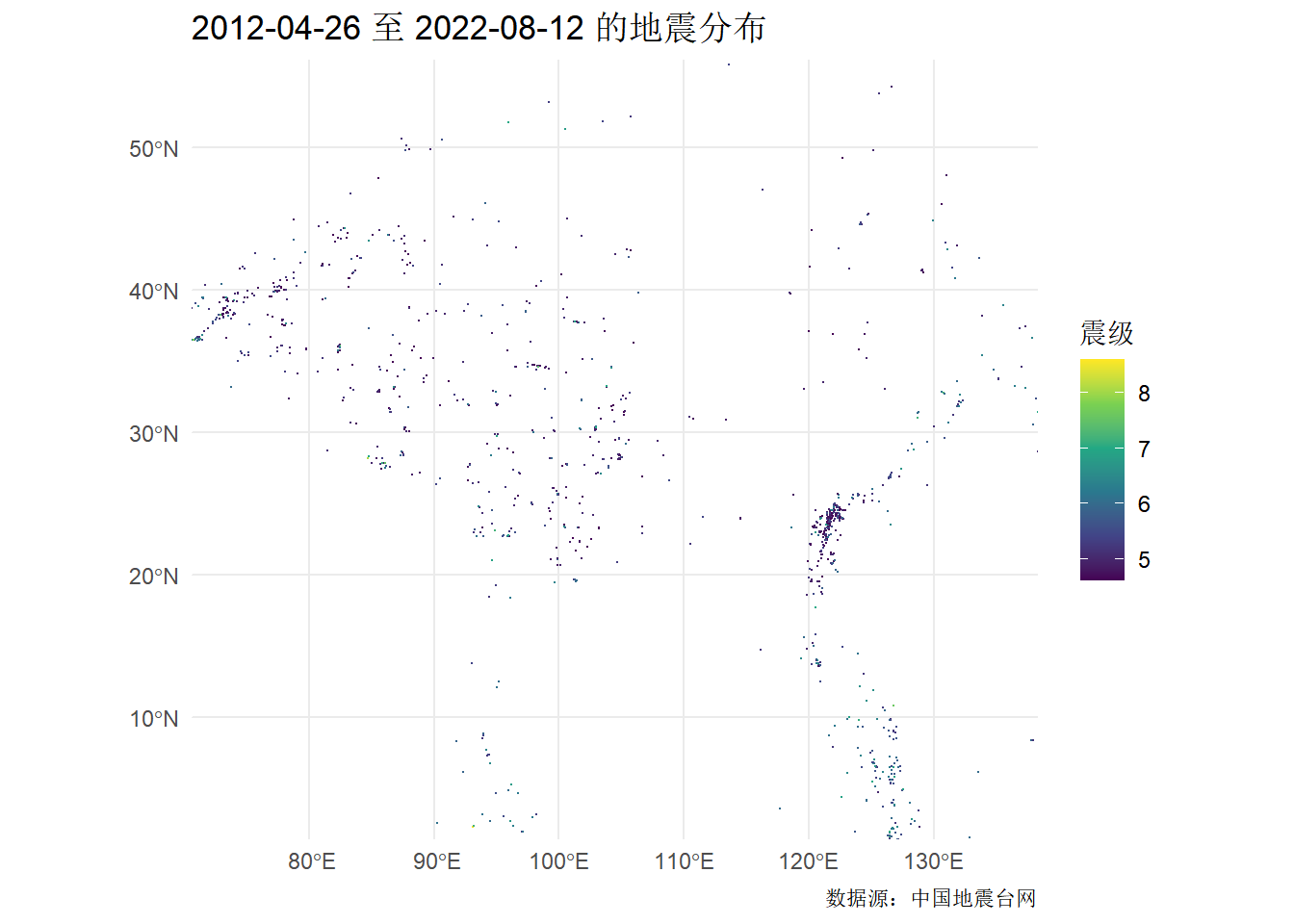
还需要加上我国的范围边界,这样才更直观。从阿里云可视化平台获取来自高德开放平台的中国地图数据,在上图添加中国地理边界和各省的边界。
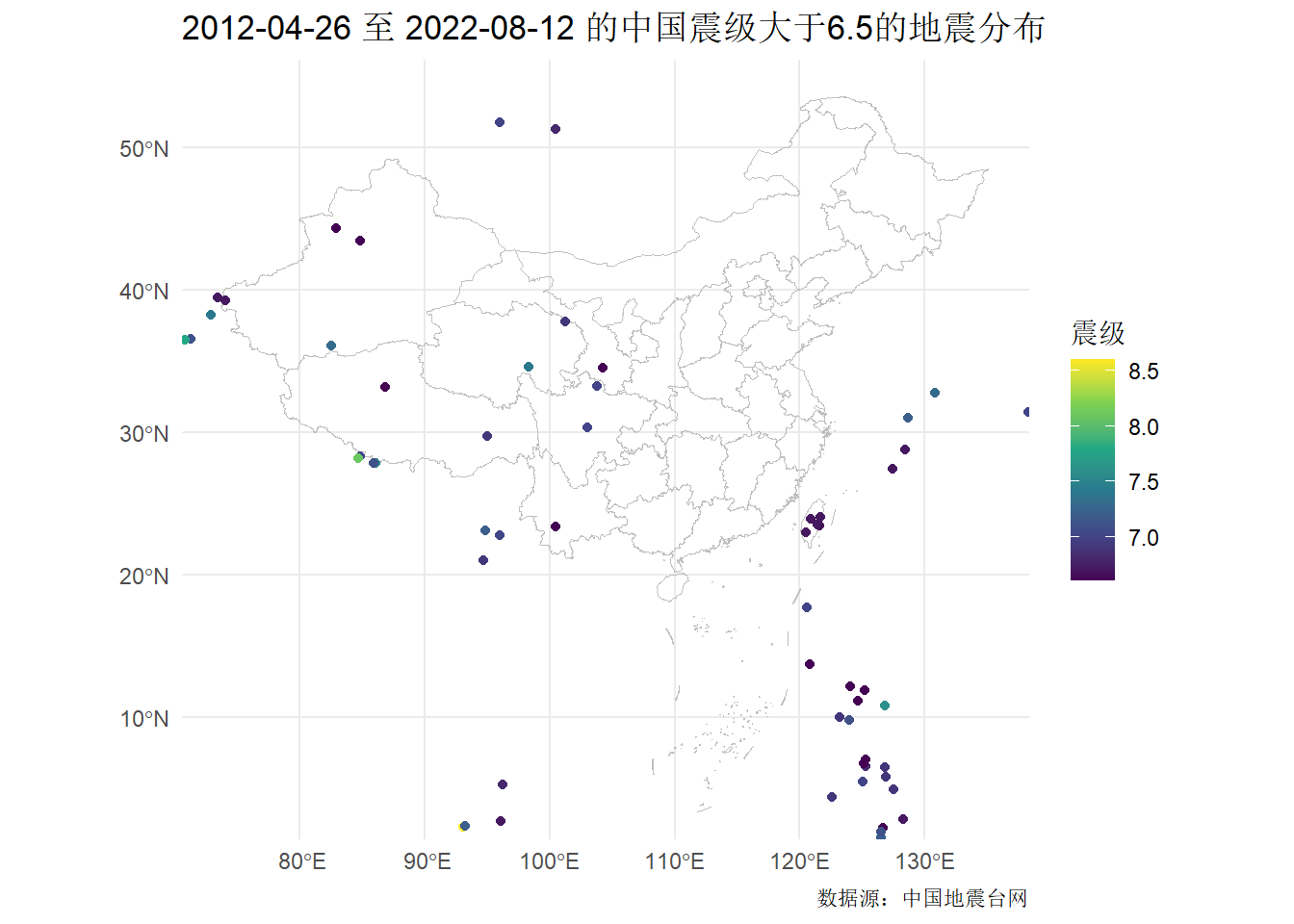
# 读取中国边界矢量地图数据
china_map <- read_sf("d:/Myblog/datas/中华人民共和国.json", as_tibble = FALSE)
# 绘制图形
ggplot() +
geom_sf(data = china_map, color = "gray", fill = NA) +
geom_sf(
data = dat_sf %>% filter(震级 > 6.5),
aes(color = 震级)
) +
scale_color_viridis_c() +
coord_sf(xlim = c(73.68, 135.2), ylim = c(3.984, 53.65)) +
theme_minimal() +
labs(
title = "2012-04-26 至 2022-08-12 的中国震级大于6.5的地震分布",
caption = "数据源:中国地震台网"
)