# A tibble: 38 × 7
compoundID case_1 case_2 case_3 control_1 control_2 control_3
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 com_001 485 154 268 350 432 425
2 com_002 208 372 219 457 324 392
3 com_003 219 125 345 473 480 403
4 com_004 289 356 116 489 376 500
5 com_005 248 456 279 457 426 436
6 com_006 323 142 462 451 354 452
7 com_007 259 148 374 397 346 383
8 com_008 428 262 226 436 499 308
9 com_009 327 494 244 316 368 401
10 com_010 480 343 495 383 471 387
# ℹ 28 more rows本篇我们实操两个实例。
1 实例1:数据重塑+批量体t检验
源数据共38行,部分如下:每行是一组,包括3个实验样本,3个控制样本;需求是批量地对每行,按实验组和控制组做t检验。
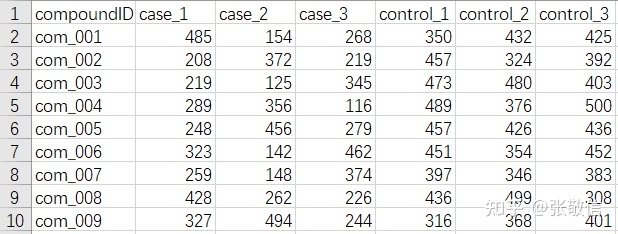
解决思路:将数据重塑为整洁型->进行批量建模。
1.1 数据重塑
我们有必要回忆下到底什么是tidyverse所倡导的整洁型数据?
- 每个变量构成一列
- 每个观测构成一行
- 每个观测的每个变量值构成一个单元格
在本例中,compoundID为实验编号,每次实验应包括实验组(case)和控制组(control),整洁的数据应该为实验编号(compoundID)-实验组别(case/control)-测定值(case/control所对应的值)。显然,原始数据并不整洁(一个实验编号对应了多个实验组别的的多个值),我们需要进行变换。
元数据中,case和control的值应该各占一列,而不是三列,需要进行整洁化操作。
# 正常方式
df %>%
pivot_longer(-compoundID,
names_to = c(".value", "index"), # ".value"放在前面,表示用"_"之前的作为值的新列名。
names_sep = "_",
values_drop_na = TRUE
) %>%
select(-index)# A tibble: 114 × 3
compoundID case control
<chr> <dbl> <dbl>
1 com_001 485 350
2 com_001 154 432
3 com_001 268 425
4 com_002 208 457
5 com_002 372 324
6 com_002 219 392
7 com_003 219 473
8 com_003 125 480
9 com_003 345 403
10 com_004 289 489
# ℹ 104 more rows# 正则表达式方式
df <- df %>%
pivot_longer(-compoundID,
names_pattern = "(.*)_",
names_to = ".value"
)- 第一个参数为选择要变形的列
- 正常宽变长是,把列名根据
_分开,第一部分case、control 继续留作列名,第二部分1、2、3 取个新列名存放。这里因为后续用不着它们,换一种写法:names_pattern是用正则表达式,识别列名中你想要用的信息,用括号括起来,这里是_之前的部分,这部分的用途是继续作为列名,通过 names_to=“.value” 完成该设定。
第一次宽表变长表后,我们发现数据仍旧不是整洁的,case和control不应该是列名,而应该是分组变量的值,那么我们继续做第二次变换。
df <- df %>%
pivot_longer(-compoundID,
names_to = "grp",
values_to = "val"
)
df# A tibble: 228 × 3
compoundID grp val
<chr> <chr> <dbl>
1 com_001 case 485
2 com_001 control 350
3 com_001 case 154
4 com_001 control 432
5 com_001 case 268
6 com_001 control 425
7 com_002 case 208
8 com_002 control 457
9 com_002 case 372
10 com_002 control 324
# ℹ 218 more rows1.2 批量t检验
批量做统计检验是一种很常见的应用场景,通常的思路为数据集分割成多个数据框+循环迭代做统计检验+合并统计结果。其实在Tidyverse中,有更简单的解法,即利用group_by()进行分数统计。
Tidyverse中的分组统计已经为我们设计好分组+分别操作+合并操作的整套逻辑,只需要我们按照需求进行分组后,写对其中一组数据进行的操作即可。
# A tibble: 38 × 16
compoundID estimate estimate1 estimate2 .y. group1 group2 n1 n2
* <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr> <int> <int>
1 com_001 -100 302. 402. val case control 3 3
2 com_002 -125. 266. 391 val case control 3 3
3 com_003 -222. 230. 452 val case control 3 3
4 com_004 -201. 254. 455 val case control 3 3
5 com_005 -112 328. 440. val case control 3 3
6 com_006 -110 309 419 val case control 3 3
7 com_007 -115 260. 375. val case control 3 3
8 com_008 -109 305. 414. val case control 3 3
9 com_009 -6.67 355 362. val case control 3 3
10 com_010 25.7 439. 414. val case control 3 3
# ℹ 28 more rows
# ℹ 7 more variables: statistic <dbl>, p <dbl>, df <dbl>, conf.low <dbl>,
# conf.high <dbl>, method <chr>, alternative <chr>2 实例2:多选答题卡并评分
首先准备数据:
- 答题卡数据:数据中每行为一个学生,每一列是一道题目。
library(tidyverse)
ans_sheet <- tibble(
Q1 = c("AB", "ACD", "A", "ABCD"),
Q2 = c("ABCD", "ACD", "ABC", "A"),
Q3 = c("ABCD", "ABC", "AD", "C")
)
ans_sheet# A tibble: 4 × 3
Q1 Q2 Q3
<chr> <chr> <chr>
1 AB ABCD ABCD
2 ACD ACD ABC
3 A ABC AD
4 ABCD A C - 正确答案数据:
# A tibble: 3 × 2
question ans
<chr> <chr>
1 Q1 ABCD
2 Q2 ACD
3 Q3 ABC 2.0.1 数据重塑
- 数据整洁化:
ans_sheet <- ans_sheet %>%
mutate(ID = 1:4) %>%
pivot_longer(-ID,
names_to = "question",
values_to = "sel"
)- 整洁化数据与正确答案连接,以方便对比。值得注意的是,每个考生在填写答案时,不一定是按照字母顺序作答,如答题卡上是”ACB”,如果正确答案为”ABC”也应该是正确的,所以在连接的同时,还应将答案进行拆分,以适配以上情况的出现。
- 对
sel和ans两列逐行迭代评分。此处的逻辑是:全选对得2分,部分对得1分,其他情况不得分。
按照问题分解的思维,我们先解决一个作答、一个答案的评分问题,再将单独的思路批量用在整个数据框中:
# 解决一个作答、一个答案的评分问题
f <- function(x, y) {
if(identical(x, y)) 2
else if(identical(intersect(x, y), x)) 1
else 0
}
# 测试
f(unlist(df[[1, 3]]), unlist(df[[1, 4]]))[1] 1- 批量应用至原数据,并进行分组统计(1个ID代表1个学生)
3 小结
通过两个例子,我们不难发现,在实际应用中,数据重塑(数据清洗、数据整理)的工作往往占了很大的比重,当数据整理好(即数据整洁化后),整个分析的过程其实已经解决大半了。