# A tibble: 93 × 5
地区 人口数_男 人口数_女 性别比 区域
<chr> <int> <int> <dbl> <fct>
1 北京 8937161 8814520 101. 城市
2 天津 5610161 5322931 105. 城市
3 河北 11010407 11119188 99.0 城市
4 山西 6588788 6608849 99.7 城市
5 内蒙古 4714495 4731924 99.6 城市
6 辽宁 12626419 12946058 97.5 城市
7 吉林 5028946 5262757 95.6 城市
8 黑龙江 7113464 7325934 97.1 城市
9 上海 10113562 9759518 104. 城市
10 江苏 20382260 19887007 102. 城市
# ℹ 83 more rows就展示数据而言,ggplot2可以提供丰富的作图函数。但对于数据分析来说,仅仅掌握ggplot2这套工具是远远不够的,还需要了解数据背景,探索、分析数据,获得数据洞见,只有结合这些,才知道选择最合适的图形,进而准确地传递信息,数据才能释放出应有的价值。
1 防止误差线图
很多杂志、期刊都喜欢 图 1 (a) 中带误差线的图形,但实际上误差线图可以展示的信息非常少。
图 1 中数据来自中国国家统计局 2021 年发布的统计年鉴,是分城市、镇和乡村的各省、自治区、直辖市的男女比例数据。 一般来说,各地区的性别比例不可能出现严重失调,比如男的是女的一倍,一个省要是出现如此失调的现象是非常罕见的。而图@fig-Error-bars-1 的纵轴给人感觉还有性别比为50%甚至30%的情况,纯属误导。相比而言,箱线图@fig-Error-bars-2 就好很多,既把整体情况展示出来了,又将一些性别比例离群的突出出来了,就整个图形来说,城市、镇和乡村的比较也突出出来了,占据了图的主要位置。
province_sex_ratio %>%
group_by(区域) %>%
summarize(
sd_len = sd(性别比),
mean_len = mean(性别比)
) %>%
ggplot(aes(x = 区域, y = mean_len)) +
geom_col(position = position_dodge(0.4), width = 0.4, fill = "gray") +
geom_errorbar(aes(ymin = mean_len - sd_len, ymax = mean_len + sd_len), position = position_dodge(0.4), width = 0.2) +
theme_classic() +
labs(y = "性别比(女=100)")
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_boxplot() +
theme_classic()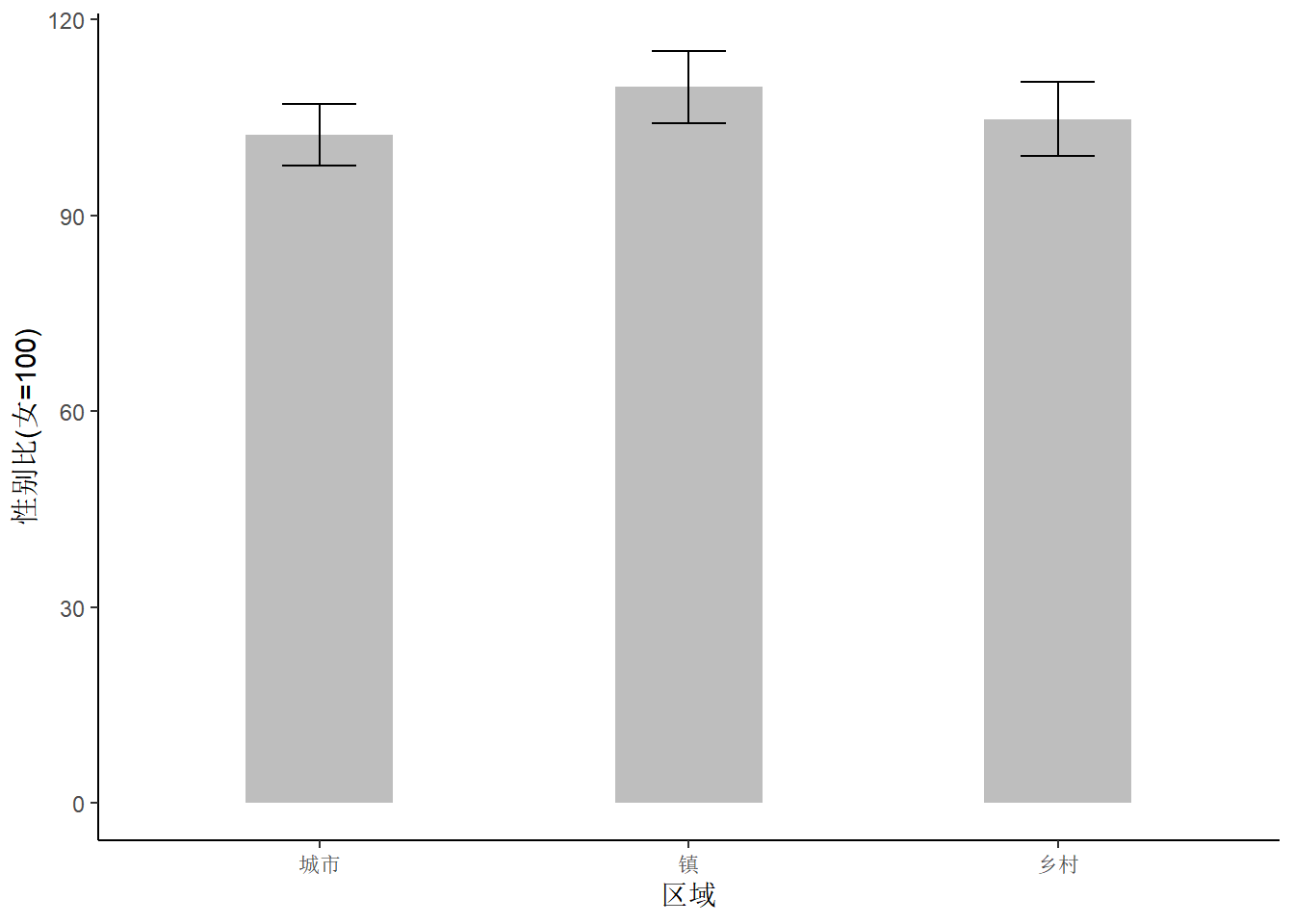

2 展示原始数据
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_point() +
theme_classic()
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_jitter(width = 0.25) + # width参数控制抖动幅度
theme_classic()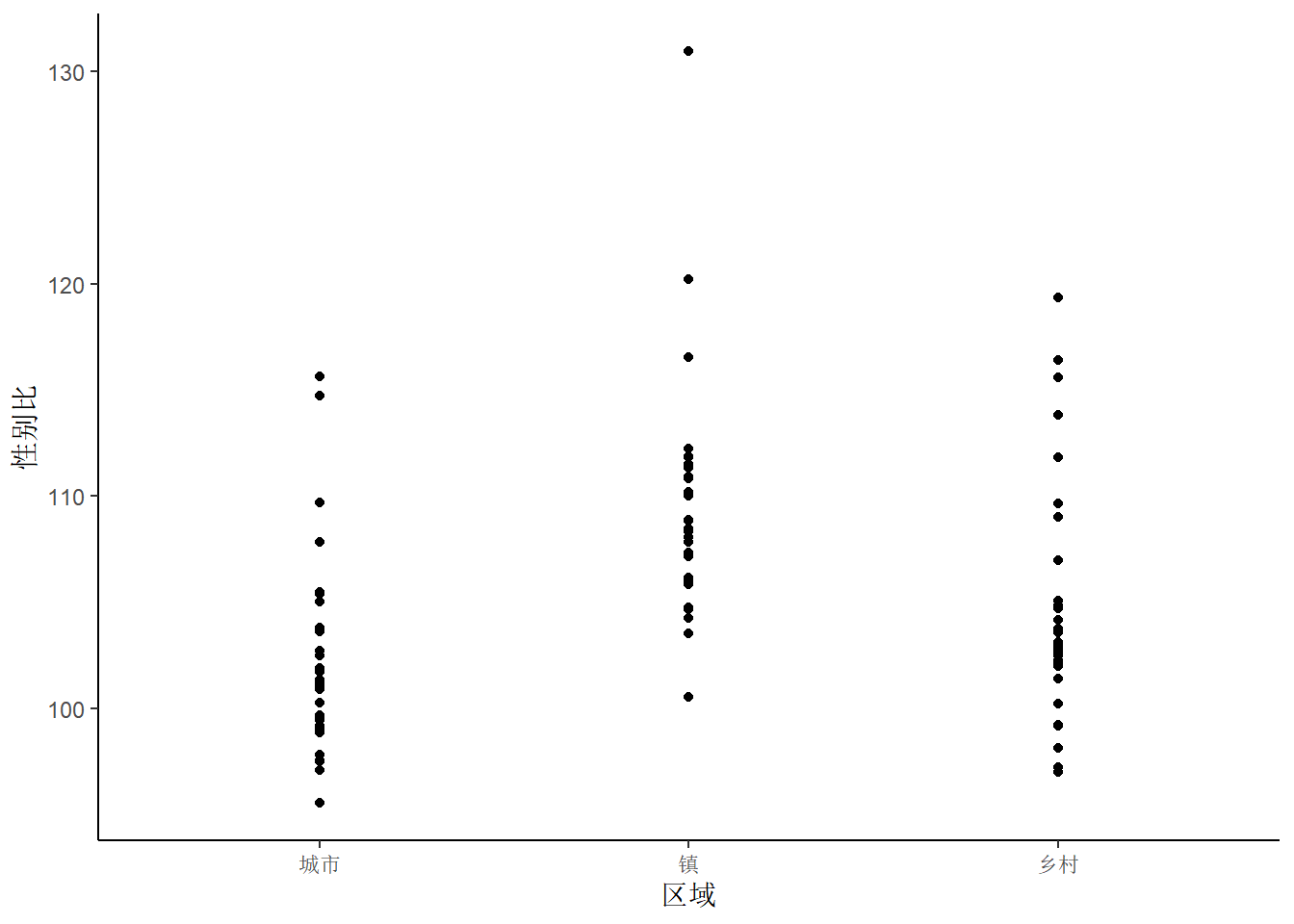
3 善用尺度变换
R语言中有很多包由核心团队持续不断地维护,我们希望观察在维护这些包中所提交的代码量的年度趋势图。
# A tibble: 360 × 3
# Groups: year, author [360]
year author revision
<dbl> <chr> <int>
1 1998 bates 30
2 1999 bates 55
3 2000 bates 64
4 2001 bates 24
5 2002 bates 11
6 2003 bates 33
7 2004 bates 11
8 2005 bates 14
9 2007 bates 9
10 2010 bates 1
# ℹ 350 more rowslibrary(geomtextpath)
trunk_year_author_sub <- trunk_year_author %>%
filter(year == 2022)
ggplot(trunk_year_author, aes(x = year, y = revision)) +
geom_textline(aes(color = author, label = author), show.legend = FALSE) +
theme_classic() +
labs(x = "年份", y = "代码提交量")
ggplot(trunk_year_author, aes(x = year, y = revision)) +
geom_textline(aes(color = author, label = author), show.legend = FALSE) +
scale_y_log10() +
theme_classic() +
labs(x = "年份", y = "代码提交量(取对数)")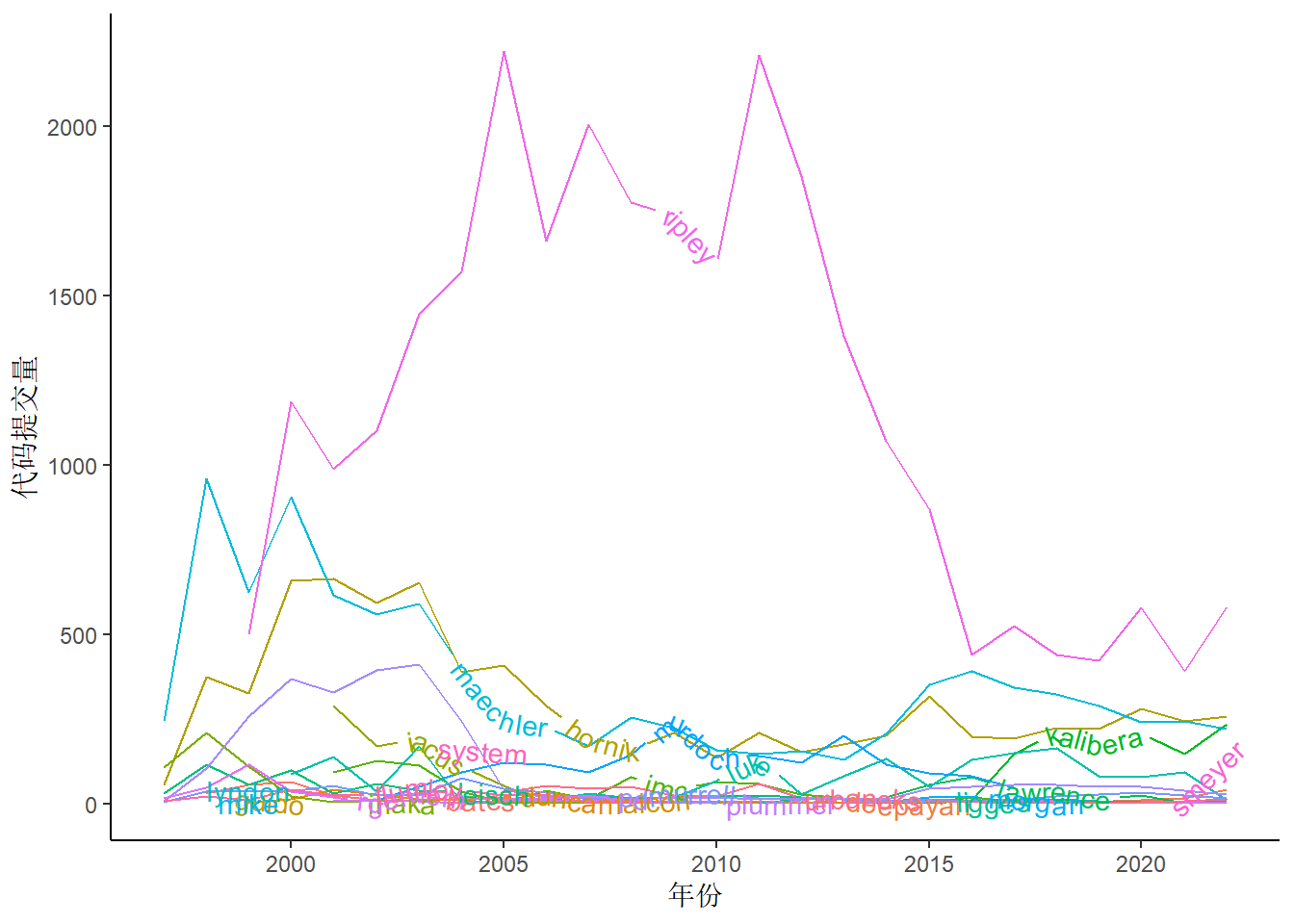
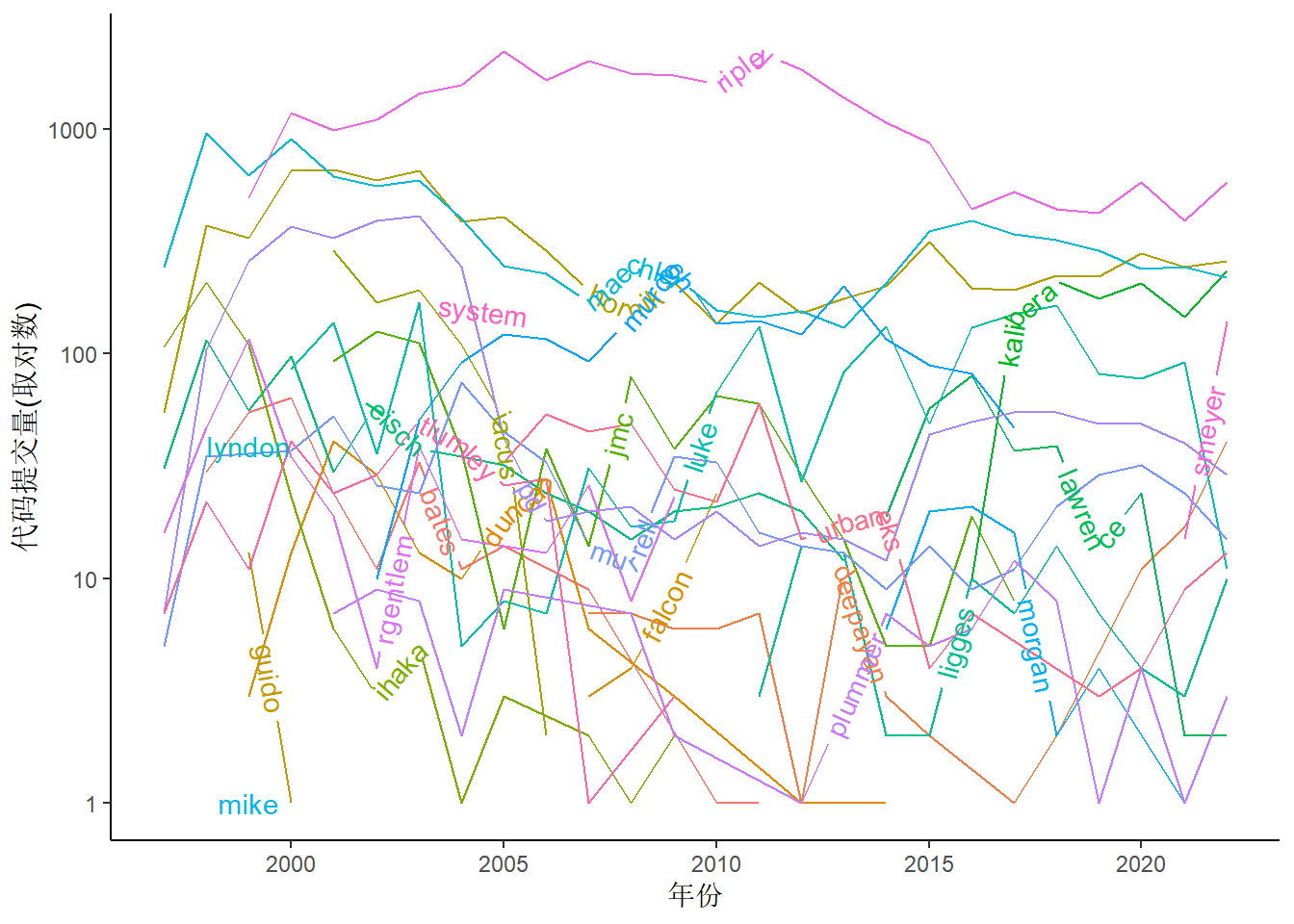
图 3 (a) 图可以看出,只有 ripley(Brian Ripley)、maechler(Martin Maechler)、hornik(Kurt Hornik) 和 kalibera(Tomas Kalibera) 明显较多,尤其是 Brian Ripley,相对而言,一些开发者的代码提交次数就很少,趋势线挤在一起,无法区分。通过对数变换,可以将相近的曲线分离,放大细节。当然,是否需要采用对数变换取决于图形目的,当想重点突出 Brian Ripley 等四人的贡献时,就不需要对数变换。
此外,如果折线图涉及的线条过多,会导致折线相互缠绕带来的不便,让图形显示较为杂乱,而栅格图不仅可以避免折线相互缠绕的现象,还可以更好地刻画时间节点。通过 图 4 ,这些情况一目了然。图中代码提交量是根据贡献者按月统计的,图例刻度同样使用了对数变换,以便展现层次感。
svn_trunk_log <- readRDS(file = "D:/Myblog/datas/ggplot2-tips/svn-trunk-log-2022.rds")
trunk_year_author_2 <- svn_trunk_log %>%
mutate(date = as.Date(format(stamp, "%Y-%m-01"))) %>%
group_by(date, author) %>%
summarise(revision = length(revision), .groups = "keep") %>%
arrange(author)
trunk_year_author_2 %>%
ggplot(aes(x = date, y = author)) +
geom_tile(aes(fill = revision)) +
scale_fill_viridis_c(trans = "log10") +
coord_cartesian(expand = FALSE) +
theme_classic() +
labs(x = "月份", y = "贡献者", fill = "代码提交量")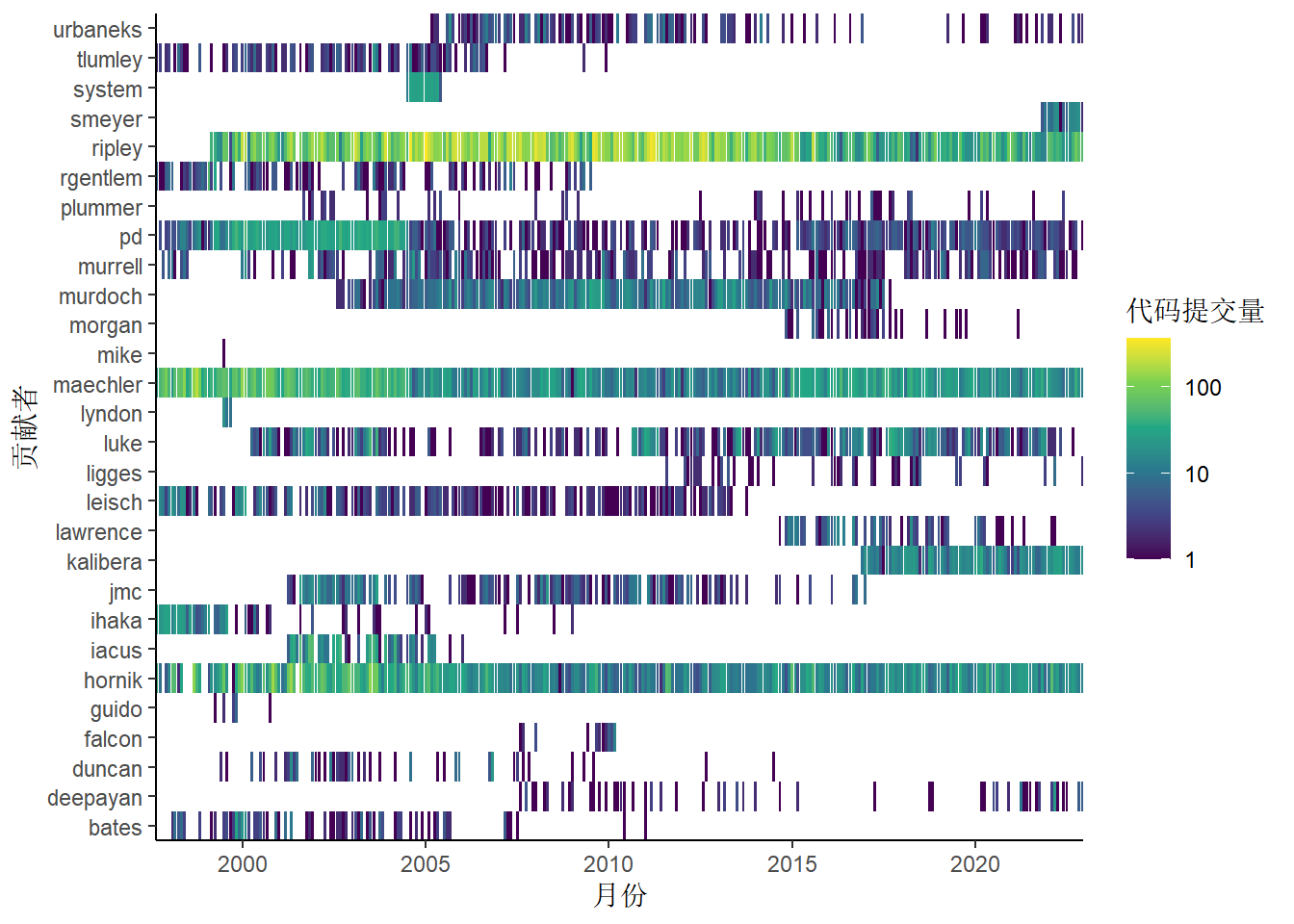
4 适当添加注释
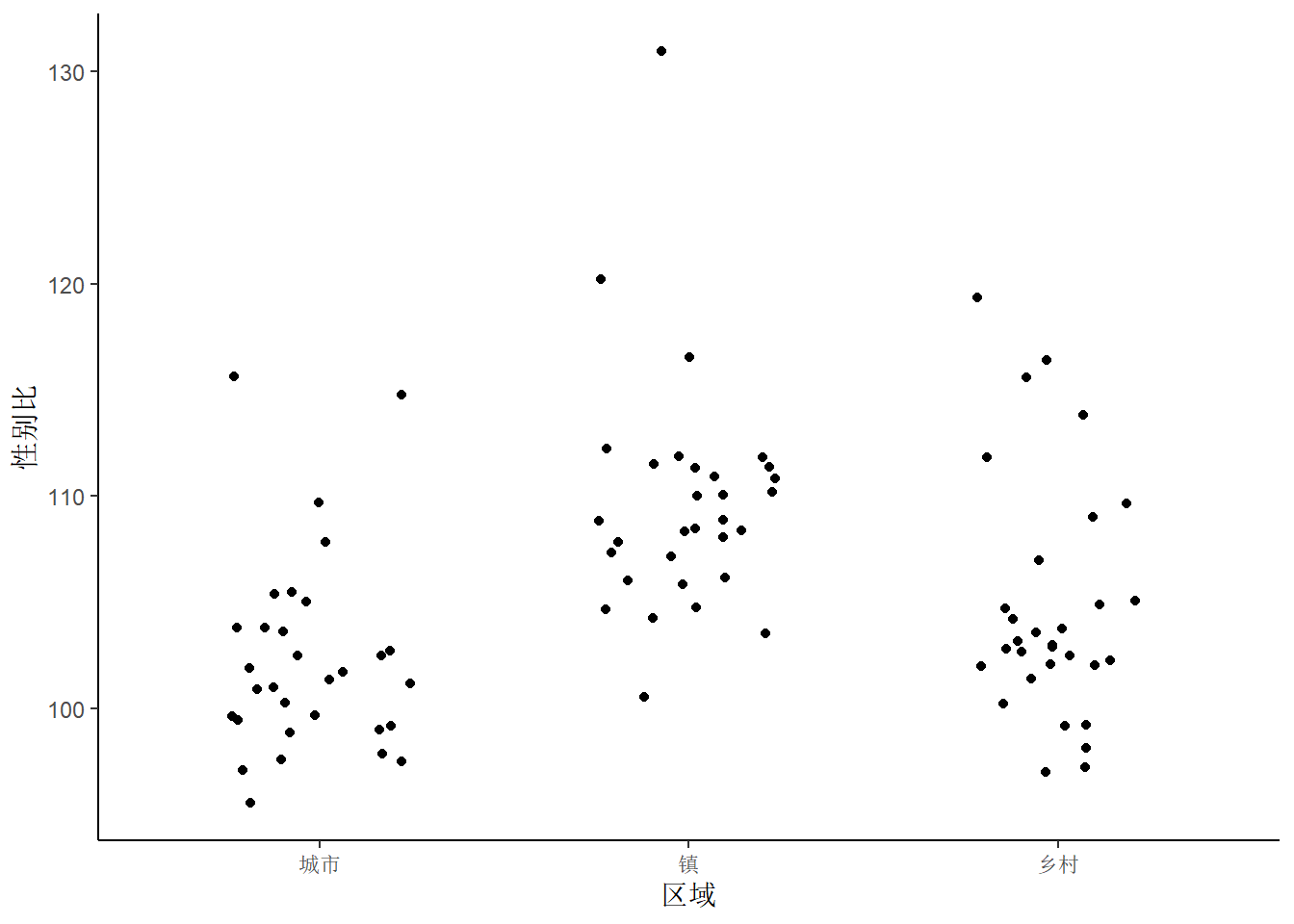
在 图 2 (b) 的图形基础上,我们希望把一些离群点标注出来作为重点研究对象。值得注意的是,对离群值的的定义应根据具体的数据情况而定。
outlier_filter <- function(x) {
# IQR():计算四分位距, quantile():计算相应位置的分位数。
# 本例中的离群值使用分位数与四分卫距的和差计算。
x < (quantile(x, probs = 0.25) - 1.5 * IQR(x)) | x > (quantile(x, probs = 0.75) + 1.5 * IQR(x))
}
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_jitter(width = 0.25) +
geom_text(aes(label = 地区),
data = function(x) subset(x, subset = outlier_filter(性别比))
)
5 结合数据背景
结合数据背景绘图具有很大的灵活性,可以通过添加参考线,刻度单位等简单、清晰的辅助信息增加可读性图形的可读性。
一般地,女性的寿命比男性的普遍要长一些,高龄女性远多于男性,之前分年龄段展示性别比数据时,也说明了这一点。人口学家认为新生儿正常的人口比约为 104,在人口统计学上,一般正常范围在 102 至 105 之间,亚洲一些国家重男轻女思想根深蒂固,往往远高于此区间。因此,图 6 将参考线设为性别比 100 是不合适的,而应该结合人口统计数据的背景,设置为 104 图 7。
set.seed(2022)
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_jitter(width = 0.25) +
geom_text(aes(label = 地区),
data = function(x) subset(x, subset = outlier_filter(性别比))
) +
theme_classic() +
geom_hline(yintercept = 100, linewidth = 0.8, lty = 2, color = "gray")
ggplot(province_sex_ratio, aes(x = 区域, y = 性别比)) +
geom_jitter(width = 0.25) +
geom_text(aes(label = 地区),
data = function(x) subset(x, subset = outlier_filter(性别比))
) +
theme_classic() +
geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray")
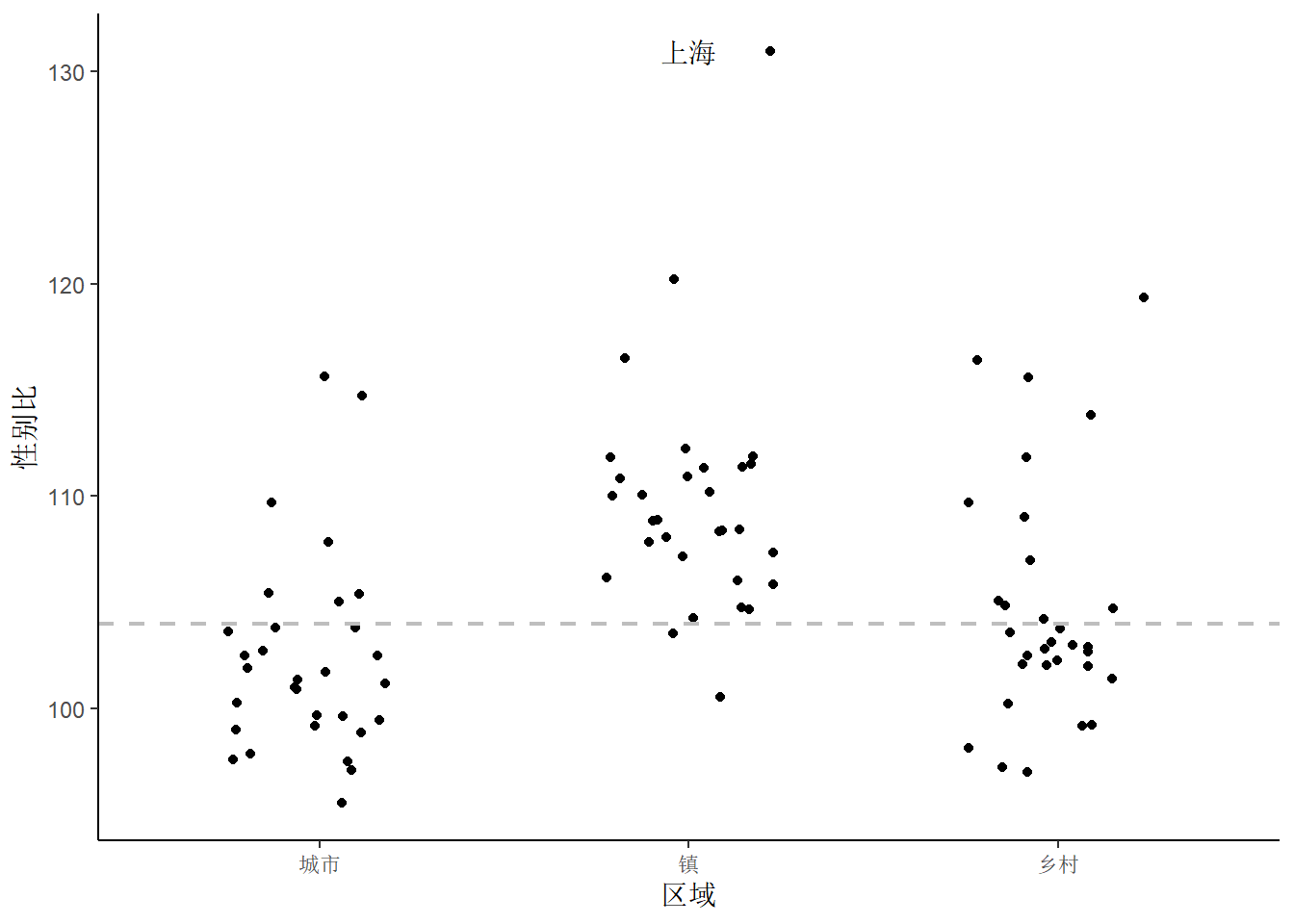
由上图也不难看出,城市里女性占比更多,说明女性往城里跑,而小镇青年留下的大多是男性,农村老太太远多于老大爷。城市里,大龄女青年很多,小镇里大龄男青年很多,适龄区间的男女性别比在空间区域上严重失衡,也是造成新生儿出生率低的原因之一。
6 简单胜过复杂
province_sex_ratio %>%
group_by(区域) %>%
summarise(性别比 = mean(性别比)) %>%
ggplot(aes(x = 区域, y = 性别比)) +
geom_bar(stat = "identity", fill = "grey", width = 0.5) +
geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray") +
scale_y_continuous(breaks = c(0, 30, 60, 90, 104), labels = c(0, 30, 60, 90, 104)) +
theme_classic()
province_sex_ratio %>%
group_by(区域) %>%
summarise(性别比 = mean(性别比)) %>%
ggplot(aes(x = 区域, y = 性别比)) +
geom_bar(stat = "identity", aes(fill = 区域), width = 0.5) +
geom_hline(yintercept = 104, linewidth = 0.8, lty = 2, color = "gray") +
scale_fill_brewer(palette = "Set1") +
theme_gray() +
labs(
title = "中国的城市、镇、乡村性别比", subtitle = "2020 年",
caption = "数据来源:国家统计局统计年鉴"
) +
theme(plot.background = element_rect(fill = "orange"))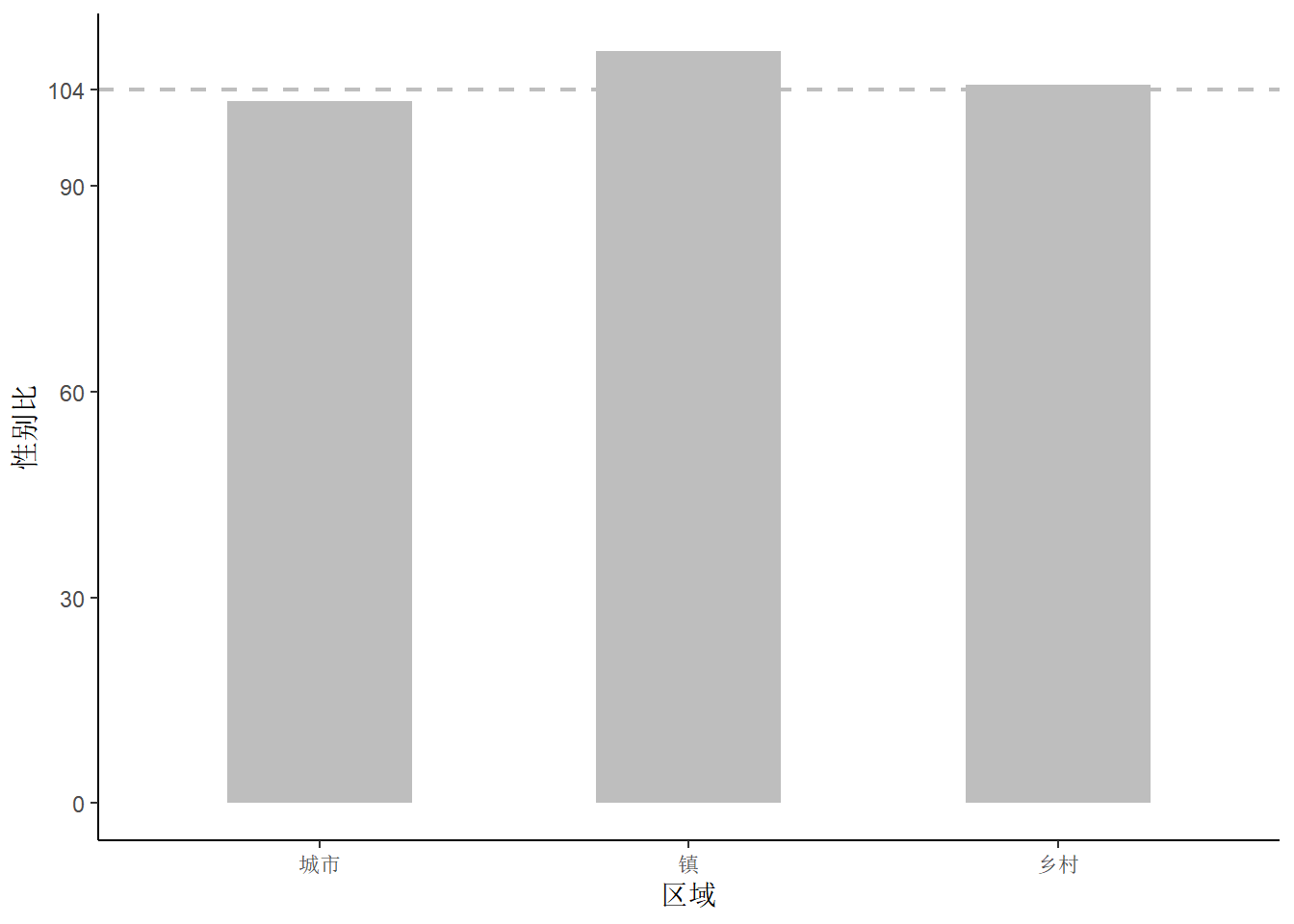
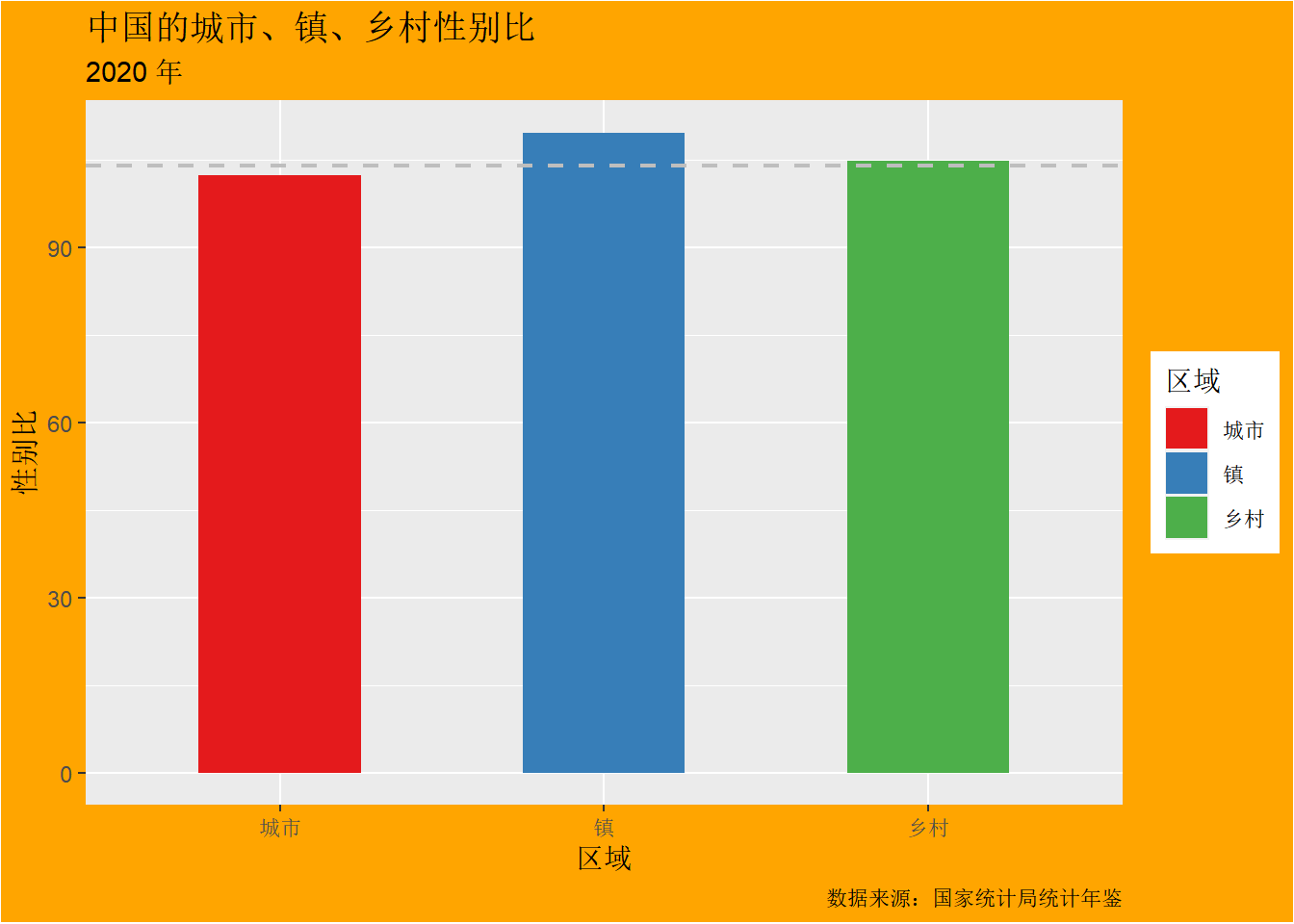
简单准确地传达数据洞见比使用各种特效、技巧有效得多。?@fig-simple 左、右两幅子图构成鲜明的对比,为了表示中国城市、镇和农村的性别比差异。图 9 额外添加了一系列复杂的元素:绘图区域设置橘黄色背景,根据区域给不同的柱子配色,添加灰色绘图主题,添加图形的主、副标题和说明,这些五颜六色的东西反而会分散读者对整个图形重点的把握。左图化繁为简,直截了当,将读者注意力快速吸引到不同柱子的高度上,没有花里胡哨的东西分散宝贵的注意力。