library(tidyverse)
library(tidytuesdayR)
emissions <- readr::read_csv("d:/Myblog/datas/tidytuesday/emissions.csv")1 说明
Carbon Majors 是一个包含全球 122 家最大的石油、天然气、煤炭和水泥生产商历史生产数据的数据库。该数据用于量化这些实体的直接运营排放和燃烧其销售产品所产生的排放,数据库中包含了低、中、高粒度的数据。本次练习的数据集就来自该数据库。
该数据可以追溯到 1854 年,包含超过1.42万亿吨二氧化碳当量(CO2e),涵盖自 1751 年工业革命开始以来全球化石燃料和水泥排放的72%。
2 准备数据
数据集包含:年份(year)、实体(parent_entity)、实体类型(parent_type)、商品(commodity)、商品生产量(production_value)、商品单位(production_unit)和总排放量(total_emissions) 7个变量(列)共12551条记录(行)。
3 数据探索及预处理
我国是煤炭大国,本次练习我们重点关注各种煤(coal类别的排放数据)的情况。
all_coal <- emissions |>
filter(str_detect(tolower(commodity), "coal")) |> # 筛选煤炭数据,并转为小写
group_by(parent_entity, parent_type, year, production_unit) |>
summarize(production_value = sum(production_value)) |>
ungroup() |>
# 新建一列,表示哪个实体在2022年仍然生产煤炭(以parent_entity列为分组单位)
mutate(still_coal = any(2022 %in% year), .by = parent_entity) |>
filter(year >= 1940) |>
group_by(parent_entity) |>
arrange(year) |>
mutate(
latest_value = production_value[which.max(year)], # 最新一年的煤炭产量
entity_x = min(year) # 实体开始生产煤炭第一年
) |>
ungroup() |>
filter(latest_value > 70) |> # 筛选最新一年煤炭产量大于70unit的实体
filter(still_coal) |> # 筛选仍然生产煤炭的实体
mutate(
parent_entity = str_remove(parent_entity, " \\(Coal\\)"), # 移除"(Coal)"字符串
entity = fct_reorder(parent_entity, -latest_value)
) # 按实体开始生产煤炭第一年排序
# View(all_coal)以上代码对emissions的数据进行了预处理,主要进行了以下步骤:
- 使用
filter筛选出包含”coal”的煤炭数据,并将商品名称转换为小写。 - 使用
group_by对实体、实体类型、年份、生产单位进行分组。 - 使用
summarize计算生产值的总和。 - 使用
mutate创建一列,表示哪个实体在2022年仍然生产煤炭,并进行了一些数据操作。 - 使用
filter筛选出年份大于等于1940的数据。 - 使用
group_by对实体进行再次分组,使用arrange对年份进行排序。 - 使用
mutate计算最新一年的煤炭产量和实体开始生产煤炭的第一年。 - 使用
filter筛选出最新一年煤炭产量大于70unit并且仍然生产煤炭的实体。 - 使用
mutate对parent_entity进行字符串处理,移除”(Coal)“字符串,并对实体开始生产煤炭的第一年进行排序。
综合来看,以上代码的主要功能是对从emissions数据集中筛选出煤炭数据,计算相关统计指标,并对数据进行整理和筛选,以便进一步分析煤炭生产情况。
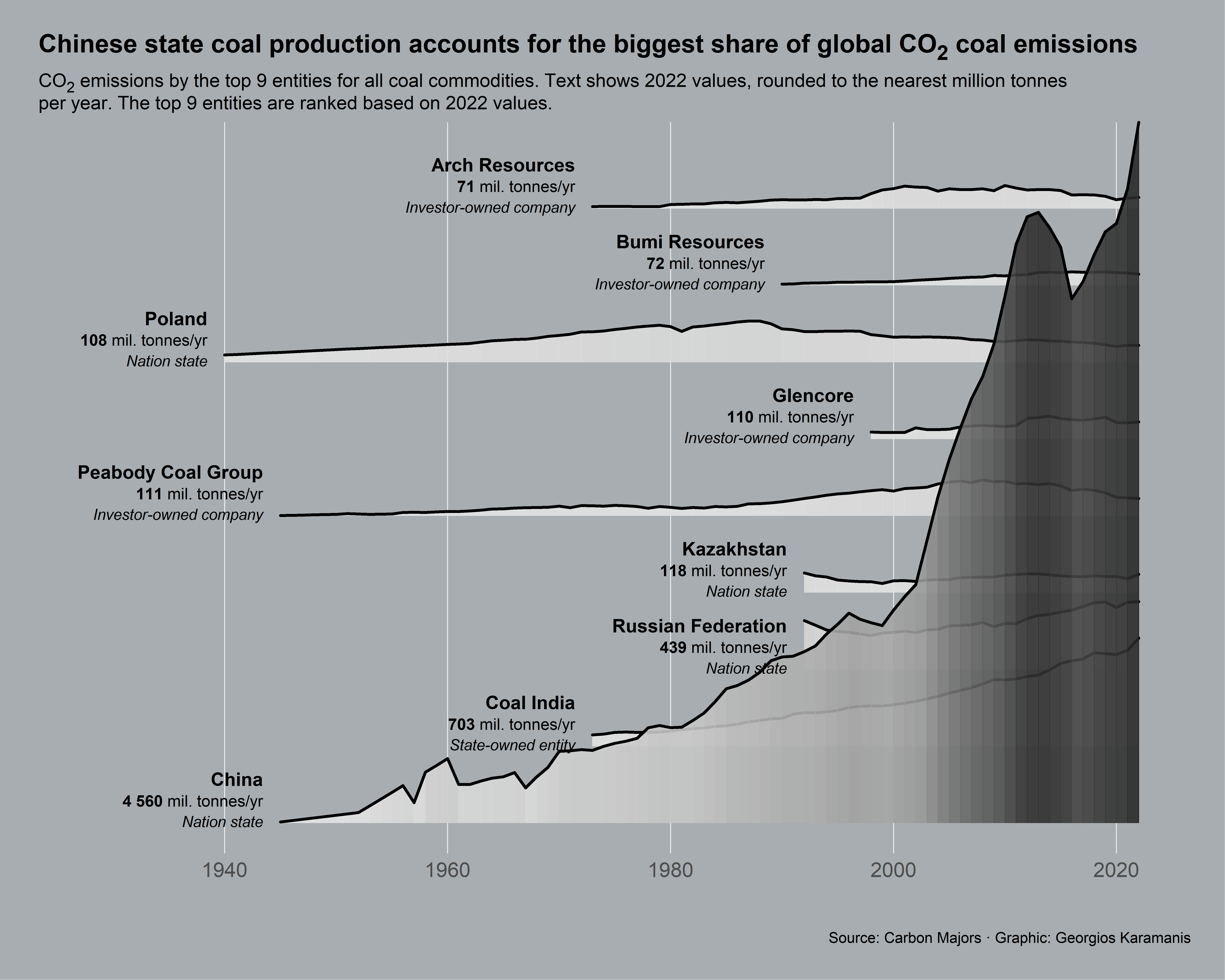
4 可视化
ggplot(all_coal) +
ggridges::geom_ridgeline_gradient(
aes(
x = year, height = production_value,
y = parent_entity, fill = production_value
),
scale = 0.002, linewidth = 0.8
) +
# label
ggtext::geom_richtext(
data = all_coal |> filter(latest_value == production_value),
aes(
x = entity_x, y = entity,
label = paste0("**", parent_entity, "**<br><span style = 'font-size:9.5pt'>**", scales::number(round(latest_value)), "** mil. tonnes/yr</span><br>", "<span style = 'font-size:9pt'>*", str_to_sentence(parent_type), "*</span>")
),
nudge_x = -1, hjust = 1, vjust = 0.2, color = "black",
lineheight = 1.1, fill = NA, label.color = NA
) +
scale_fill_gradient(
high = alpha("grey10", 0.90),
low = alpha("grey90", 0.9)
) +
scale_x_continuous(
expansion(0),
limits = c(1928, 2022), breaks = c(1940, 1960, 1980, 2000, 2020)
) +
scale_y_discrete(expand = expansion(mult = 0.05)) +
coord_cartesian(clip = "off") +
labs(
title = "Chinese state coal production accounts for the biggest share of global CO<sub>2</sub> coal emissions",
subtitle = "CO<sub>2</sub> emissions by the top 9 entities for all coal commodities. Text shows 2022 values, rounded to the nearest million tonnes<br>per year. The top 9 entities are ranked based on 2022 values.",
caption = "Source: Carbon Majors · Graphic: Georgios Karamanis"
) +
theme_minimal() +
theme(
legend.position = "none",
plot.background = element_rect(fill = "#A8ADB1", color = NA),
axis.text.y = element_blank(),
axis.text.x = element_text(size = 12),
axis.title = element_blank(),
panel.grid.minor = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.major.x = element_line(linewidth = 0.3),
plot.margin = margin(20, 20, 20, 20),
plot.title = ggtext::element_markdown(face = "bold", size = 15),
plot.subtitle = ggtext::element_markdown(),
plot.caption = element_text(margin = margin(30, 0, 0, 0))
)