正则表达式(Regular Expression,简称regex)是一种用于匹配字符串的模式,它使用特定语法描述字符的规律。它可以帮助我们从看似杂乱的文本中查找、替换和提取特定的字符或字符串,从而实现文本的批量处理。正则表达式在数据清洗、文本处理和自然语言处理等领域非常有用。
这篇文章 有助于我们更好的理解正则表达式。
主流编程语言都支持正则表达式,它广泛用于文本处理,例如:
- 检测模式是否存在
- 定位匹配内容位置
- 提取目标信息
- 替换(修改)文本
正则表达式学习建议:
- 从最常用的三个实例场景入手:
- 直接匹配
- 零宽断言匹配标志间的内容
- 分组捕获
- 遇具体问题时,查语法表 → 尝试构造 → 调试成功
- 越用越提高
1 正则表达式的基本语法
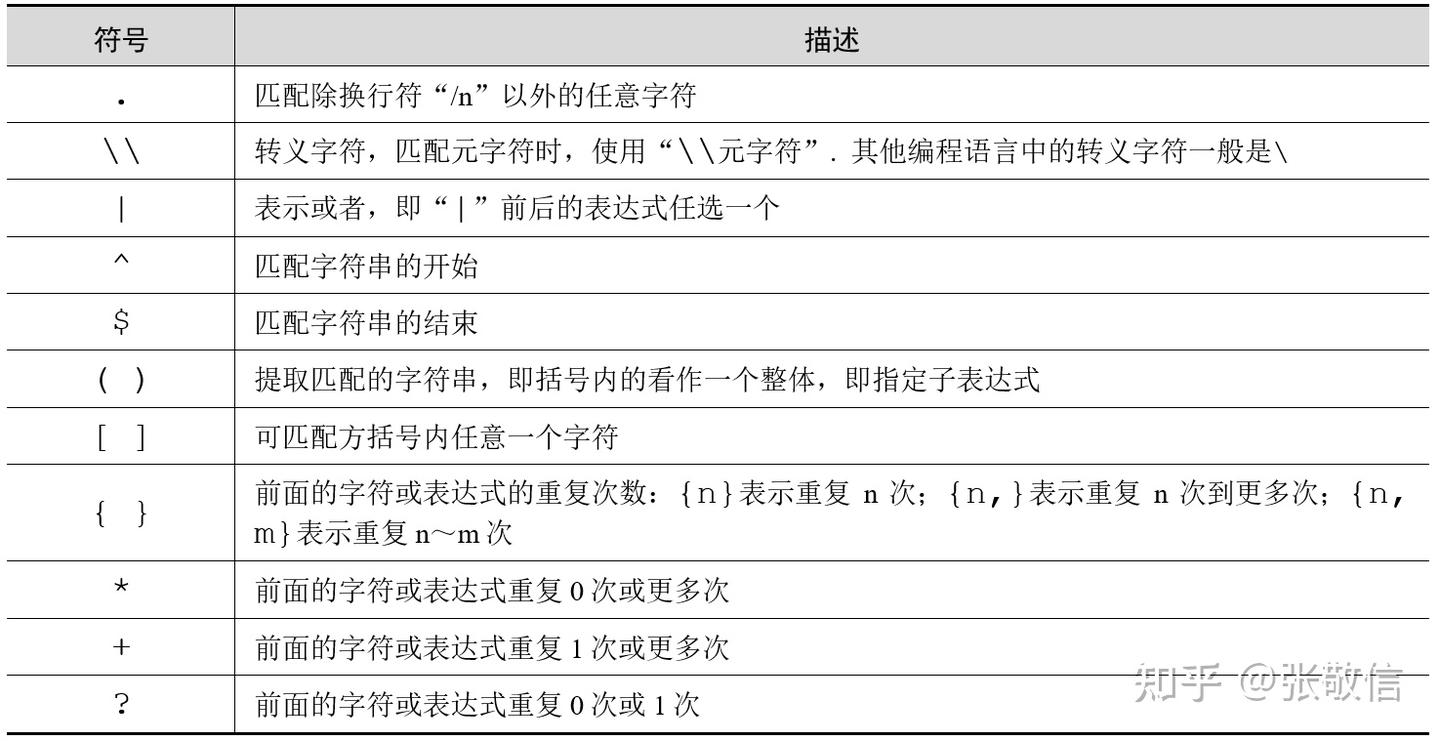
正则表达式的本质是字符串,由普通字符(字母、数字、标点等)和特殊字符(元字符)组成。元字符具有特殊含义,用于定义匹配模式。
正则表达式作为表达式同样有运算优先级规则:
-
括号分组:圆括号
()内的表达式优先级最高,用于明确子表达式的边界。 -
重复操作符:量词
*、+、{}(控制前一项的重复次数)次之。 -
字符连接:多个字符连续排列时(如
abc),按顺序隐式连接匹配。 -
或运算:
|表示的分支选择(或运算)优先级最低。
stringr全面支持正则表达式,并且提供了更简洁的函数接口,推荐使用。以下是一些常用函数:
-
str_view(): 调试和查看匹配效果。 -
str_detect(): 检测是否匹配到。 -
str_extract(): 提取匹配到的内容。 -
str_replace(): 替换匹配到的内容。
1.1 元字符和特殊字符
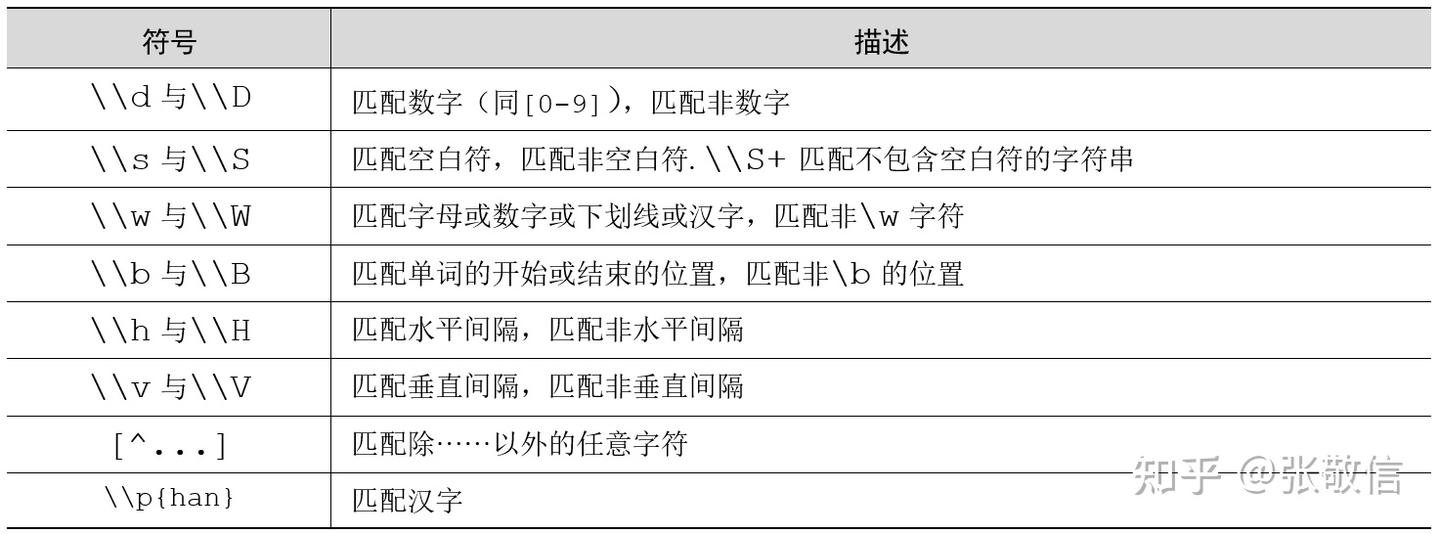
在了解元字符和特殊字符之后,我们就可以利用它们书写一些简单的正则表达式了:
匹配有abc开头的字符串:
^abc。-
匹配8位数字的QQ号码:
-
^\\d\\d\\d\\d\\d\\d\\d\\d$。 -
^\\d{8}$。
-
-
匹配1开头11位数字的手机号码:
-
^1\\d\\d\\d\\d\\d\\d\\d\\d\\d\\d$。 ^1\\d{10}$
-
匹配以a开头、0个或多个b结尾的字符串:
^ab*b$
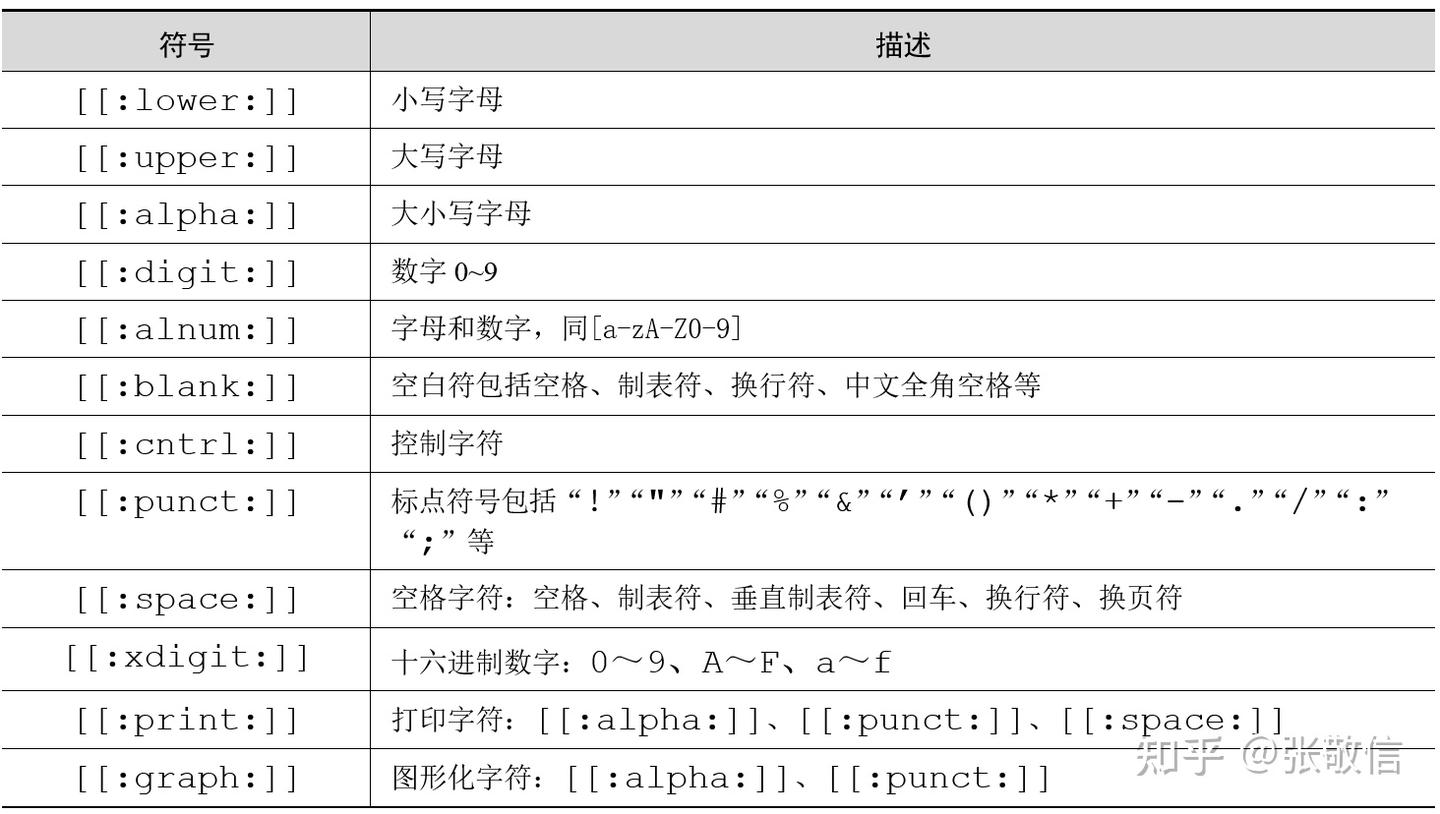
1.2 POSIX字符类
在模式中方括号内可以用[:alpha:] 表示任意一个字母。 比如,[[:alpha:]]匹配任意一个字母(外层的方括号表示字符集合, 内层的方括号是POSIX字符类的固有界定符)。
1.3 分组
上面的例4中,限定符 * 是作用在它左边最近的一个字符,如果想ab同时被*限定那怎么办呢?
正则表达式中用小括号
()来做分组,也就是括号中的内容作为一个整体。
因此当我们要匹配多个ab时,我们可以这样写:^(ab)*$
1.4 转义
我们看到正则表达式用小括号来做分组,那么问题来了:
如果要匹配的字符串中本身就包含小括号,那是不是冲突?应该怎么办?
针对这种情况,正则提供了转义的方式,也就是要把这些元字符、限定符或者关键字转义成普通的字符,做法很简答,就是在要转义的字符前面加个斜杠,也就是\即可。值得注意的是,R语言中的转义符号为\\。 如:要匹配以(ab)开头,需要用如下表达式:^(\\(ab\\))$
1.5 条件-或
回到我们刚才的手机号匹配,我们都知道:国内号码都来自三大网,它们都有属于自己的号段,比如联通有130/131/132/155/156/185/186/145/176等号段,假如让我们匹配一个联通的号码,那按照我们目前所学到的正则,应该无从下手的,因为这里包含了一些并列的条件,也就是”或”,那么在正则中是如何表示”或”的呢?
正则表达式中用符号
|来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
那么我们可以使用或条件来处理这个问题:
^(130|131|132|155|156|185|186|145|176)\d{8}$
1.6 区间
看到上面的例子,我们发现还是有些复杂,是否可以再简化?
实际上,
正则表达式中提供了一个元字符
[]表示区间,来匹配方括号内的任意字符。
- 限定0到9可以写成
[0-9]。- 限定字母A到Z可以写成
[A-Z]。- 限定某些数字
[165]。
那么上述的联通电话号码的正则表达式可以简化为:
^(13[0-2]|15[5-6]|18[5-6]|145|176)\d{8}$
以上就是正则表达式的基本用法。下面我们需要了解一些进阶的用法。
2 正则进阶知识点
2.1 直接匹配
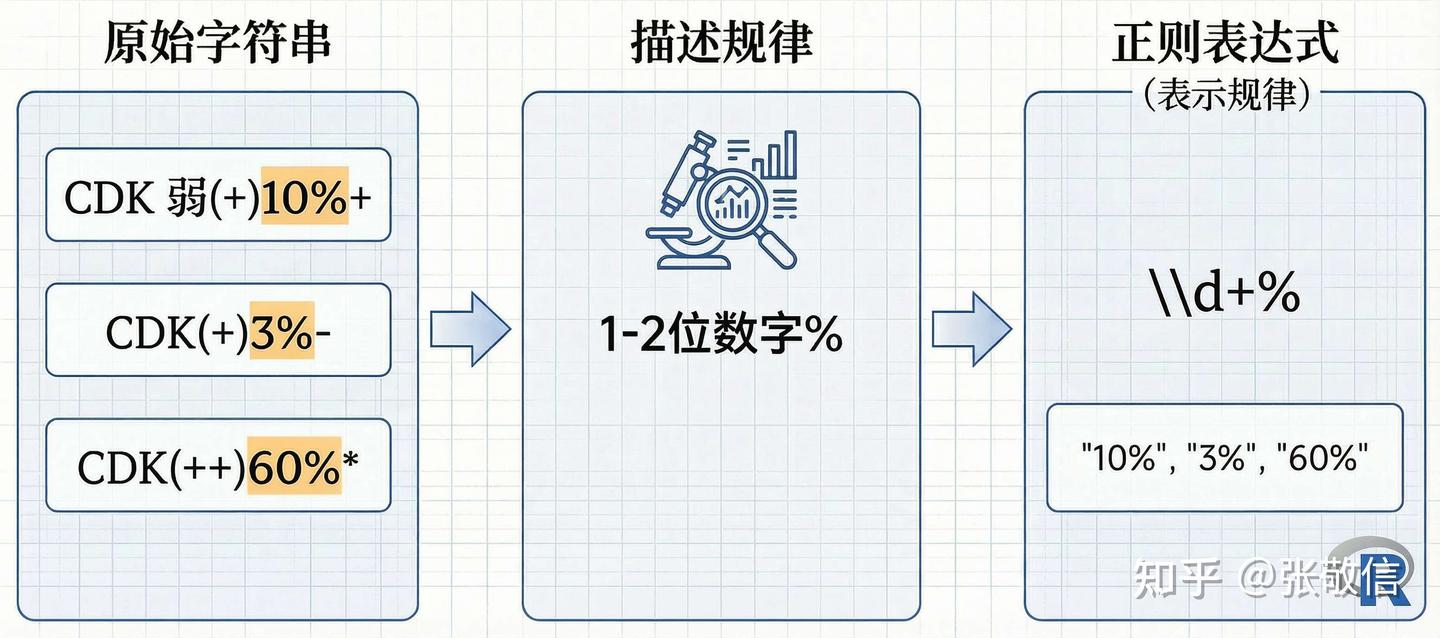
当目标内容有明确规律时(例如提取数字),直接编写正则表达式描述模式即可实现匹配,如\\d+匹配连续的数字。
[1] │ CDK弱(+)<10%>+
[2] │ CDK(+)<30%>-
[3] │ CDK(-)<0>+
[4] │ CDK(++)<60%>*2.1.1 贪婪匹配和懒惰匹配
正则表达式通常都是贪婪匹配,即重复直到文本中能匹配的最长范围。
无上限的重复匹配如*, +, {3,}等缺省是贪婪型的, 重复直到文本中能匹配的最长范围。 比如我们希望找出圆括号这样的结构, 很容易想到用\(.+\)这样的模式(注意圆括号是元字符,需要用反斜杠保护), 但是这不会恰好匹配一次, 模式会一直搜索到最后一个)为止。
例如:
str_view("(1st) other (2nd)", "\\(.+\\)")[1] │ <(1st) other (2nd)>我们本来期望的是提取两个”(1st)“和”(2nd)“组合, 不料整个地提取了”(1st) other (2nd)“。 这就是因为.+的贪婪匹配。 如果要求尽可能短的匹配, 使用*?, +?, {3,}?等”懒惰型”重复模式。 在无上限重复标志后面加问号表示懒惰性重复。 那么上述的正则表达式可以改写为:
str_view_all("(1st) other (2nd)", "\\(.+?\\)")[1] │ <(1st)> other <(2nd)>值得注意的是,懒惰匹配会造成搜索效率的降低,应仅在需要的时候使用。
2.2 零宽断言
当目标内容无规律,但被有规律的边界标志包裹时(如提取括号内的内容),用零宽断言匹配不含边界的部分:
-
肯定断言(内容紧邻指定边界):
(?<=左标志)内容(?=右标志)。 -
否定断言(内容不紧邻指定边界):
(?<!左标志)内容(?!右标志)。
零宽断言可划分为两个词:零宽和断言。
- 断言:就是我断定什么什么,即指明在指定的内容前面或后面会出现满足指定规则的内容。例如,
ss1aa2bb3,正则可以用断言找出aa2后面有bb3,也可以找出aa2前面有ss1。 - 零宽:就是没有宽度 ,表明断言只是匹配位置,不占字符,即匹配结果不会返回断言本身。
了解了定义后,我们还是通过例子来简单说明。
假设我们要用爬虫抓取csdn里的文章阅读量。通过查看源代码可以看到文章阅读量这个内容是这样的结构:
“<span class=”read-count”>阅读数:641</span>”
其中,641这个是变量,对应不同文章的不同值。当我们拿到这个字符串时,需要获得其中641的部分的正则表达式该如何匹配呢?
2.2.1 先行断言
- 语法:
?=pattern。
- 作用:匹配
pattern表达式前面的内容,不返回本身。
回到例子本身,我们要匹配641这个数字,意味着我们要匹配</span>前面的数字内容。
string_test <- "<span class=\"read-count\">阅读数:641</span>"
str_extract(string_test, ".+(?=</span>)")[1] "<span class=\"read-count\">阅读数:641"好像不对,我们只想要641的部分。
str_extract(string_test, "\\d+(?=</span>)")[1] "641"2.2.2 后行断言
有先行就有后行,先行是匹配前面的内容,那后行就是匹配后面的内容啦。 我们注意到,641也可以是表达式之后的内容,同样也可以用后行断言来处理。
- 语法:
(?<=pattern)。 - 作用:匹配
pattern表达式之后的内容,同样不返回本身。
str_extract(string_test, "(?<=<span class=\"read-count\">阅读数:)\\d+")[1] "641"2.2.3 零断宽言实例
x1 <- c(
"175.10.237.40(湖南-长沙)",
"114.243.12.168(北京-北京)",
"125.211.78.251(黑龙江-哈尔滨)"
)
# 提取省份
str_extract(x1, "(?<=\\().*?(?=-)")[1] "湖南" "北京" "黑龙江"# 提取IP地址
str_extract(x1, "^.*(?=\\()")[1] "175.10.237.40" "114.243.12.168" "125.211.78.251"# 提取专业
x2 <- c("18级能源动力工程2班", "19级统计学1班")
str_extract(x2, "(?<=级).*?(?=[0-9])")[1] "能源动力工程" "统计学" # 提取最后一个词
x3 <- c("I am a teacher", "She is a beautiful girl")
str_extract(x3, "(?<= )[^ ]+$")[1] "teacher" "girl" # 提取以“kc/”为左标志, 直到第3个下划线之前的内容
x4 <- "D:/paper/1.65_kc_ndvi/kc/forest_kc_historical_ACCESS-ESM1-5_west_1981_2014.tif"
str_extract(x4, "(?<=kc/)([^._$]+_){2}[^_]+")[1] "forest_kc_historical"上述提取IP地址的代码中:
-
^表示从字符串开头开始, -
.*表示尽可能多地匹配任意字符, - 后面的
(?=\\()是一个正向的先行断言,意思是 后面必须紧跟一个左括号,但这个左括号不被真正包含在结果里。因为在 R 字符串里,\\(才表示正则中的字面量(,所以需要双重转义。
上述提取kc/后内容的代码中:
-
(?<=kc/)是零宽后行断言,要求匹配位置前面紧跟kc/但不包含它; -
([^_]+_)匹配一个或多个非下划线字符后跟一个下划线; -
{2}表示前面的括号组恰好重复两次(即前两段带下划线的部分); -
[^_]+则匹配第三段的非下划线字符直到下一个下划线或字符串结束。
^ 出现在字符类 [] 外部时,表示匹配字符串的开头(或行首,在多行模式下);当 ^ 出现在字符类 [] 内的起始位置时,表示否定——匹配除所列字符之外的任何字符。2.3 分组与捕获
在正则表达式中用圆括号来分出组, 作用是
- 确定优先规则;
- 组成一个整体;
- 拆分出模式中的部分内容(称为捕获);
- 定义一段供后续引用或者替换。
圆括号中的模式称为子模式,或者捕获。
2.3.1 确定优先级
在使用备择模式时,James|Jim是在单词James和Jim之间选择。 如果希望选择的是中间的mes和Ji怎么办? 可以将备择模式保护起来, 如Ja(mes|Ji)m, 就可以确定备择模式的作用范围。
正则表达式有比较复杂的优先级规则, 所以在不确定那些模式组合优先采纳时, 应该使用圆括号分组, 确定运算优先级。
2.3.2 组成整体
元字符问号、加号、星号、大括号等表示重复, 前面的例子中都是重复一个字符或者字符类。 如果需要重复由多个字符组成的模式, 如x[[:digit:]]{2}怎么办? 只要将该模式写在括号中,如:
[1] │ <x01x02>x
[2] │ _<x11>x9str_extract(c("x01x02x", "_x11x9"), "(x[[:digit:]]{2})+")[1] "x01x02" "x11" 上例的元数据中, 第一个元素重复了两次括号中的模式, 第二个元素仅有一次括号中的模式。
2.4 捕获与向后引用
有时一个模式中部分内容仅用于定位, 而实际有用的内容是其中的一部分, 就可以将这部分有用的内容包在圆括号中作为一个捕获。
# 分组捕获型号(字母或数字)添加空格替换原内容, 后续可接按空格拆分列
x <- c("宝马X3 2016款", "大众 速腾2017款", "宝马3系2012款")
str_replace(x, "([a-zA-Z0-9])", " \\1") # 替换部分 " \\1" 中的 \\1 表示引用第 1 个捕获组,也就是把之前匹配到的那个字符原样放回去[1] "宝马 X3 2016款" "大众 速腾 2017款" "宝马 3系2012款" # 时分秒中间插入冒号, 后续可接hms()解析
x <- c("194631", "174223")
str_replace_all(x, "(\\d{2})", " \\1:")[1] " 19: 46: 31:" " 17: 42: 23:"# 纠正年份和国别顺序不一致问题, 年份在国别前则交换
x <- c("独行月球2022_Chinese","蜘蛛侠USA_2021","人生大事2022_Chinese")
str_replace_all(x, "(\\d+)_(.+)", "\\2_\\1")[1] "独行月球Chinese_2022" "蜘蛛侠USA_2021" "人生大事Chinese_2022"