library(psych)
fa.parallel(USJudgeRatings[, -1],
fa = "pc", n.iter = 100, show.legend = FALSE, main = NULL
)Parallel analysis suggests that the number of factors = NA and the number of components = 1 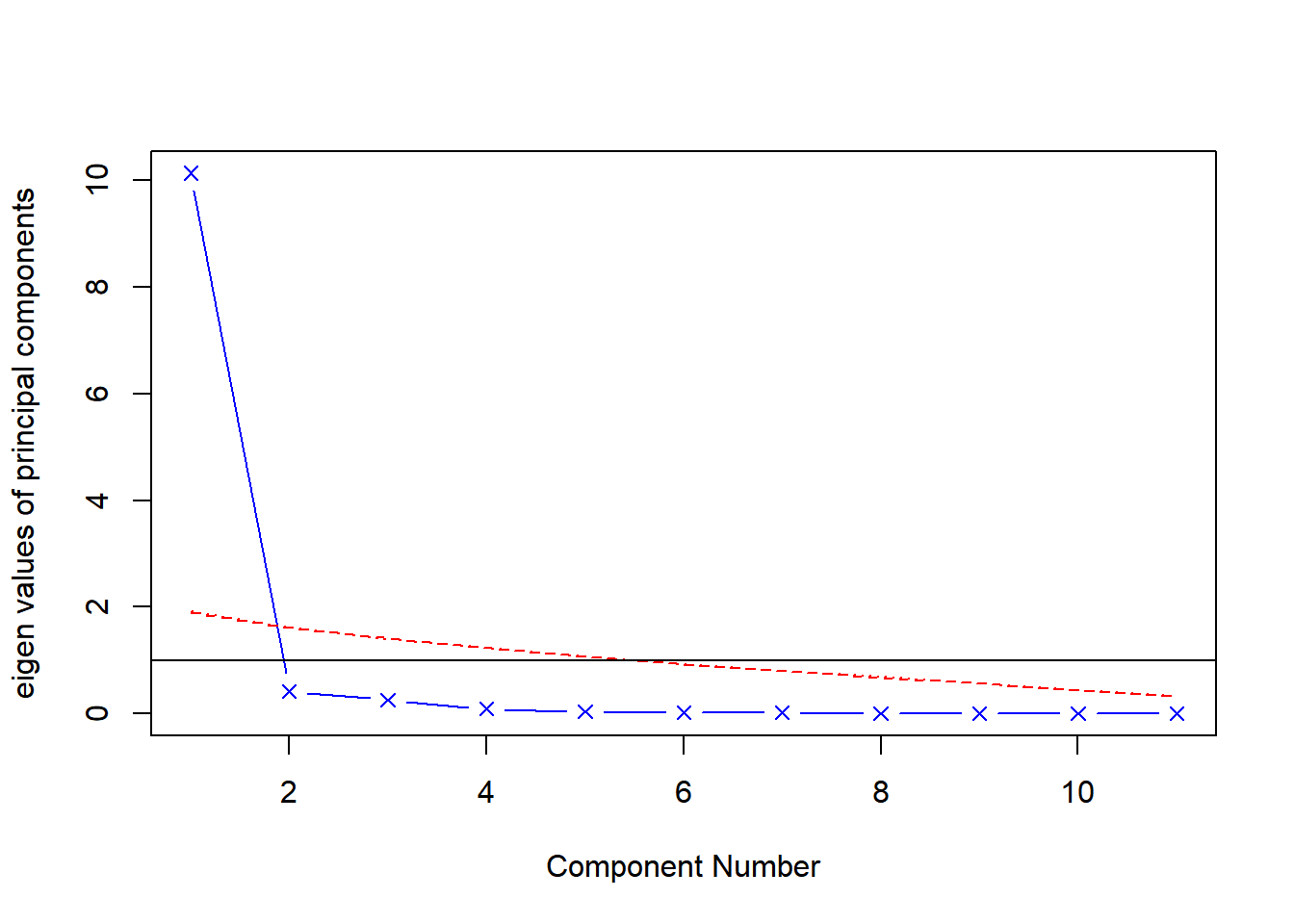
PCA(主成分分析)是一种数据降维的技巧,它能将大量相关变量转化为一组很少的不相关变量,这些不相关的变量成为主成分。例如使用主成分分析可将30个相关(但可能存在冗余)的变量转化为5个无关的成分变量,并且尽可能的保留原始数据集的信息。
PCA可以理解为挑选最相关的变量线性组合,并在预测模型中使用它们。PCA有助于我们找出数据中变化量最大的变量,同时它也是一种解决数据共线性1问题的方式。
以下两个因素会使得数据的维度变得非常高:
首先是具有不同级别的分类变量。
其次是数据集中的冗余变量。
当所构建的模型中包含分类变量时,我们使用虚拟变量,并且分类变量中的级别数越多,我们创建的虚拟变量就越多,这会增加维度。冗余变量2代表数据集中的信息不够精简,多个特征描述了同一信息。
冗余变量和共线性会造成许多问题,如破坏参数估计的稳定性、混淆模型解释、增加过拟合风险等。一个最佳的回归模型,应该保证每个预测变量与目标(输出)变量均相关,但相互之间几乎没有关联。如果预测变量本身之间的相关性很高,那么拟合出的模型及时在训练集有较高精度,也可能无法在测试集上得到满意的效果。所以在数据分析前,检测数据的共线性十分重要。
如果模型中的R平方值很大,则模型的F检验是显著的,但系数估计的t检验不是显著的,此时可能存在多重共线性。
如果变量之间的相关性很大,则存在多重共线性。
通过方差膨胀因子VIF( Equation 1)来检测的多重共线性。
VIF的计算公式如下:
\[ VIF = \frac{1}{1-R^2} \tag{1}\]
当VIF的值大于10,则表明变量之间存在严重的相关性。
在R中有许多方法可以对模型的共线性进行检测。当存在共线性情况时,建议采取如下补救措施:
检查其中一个变量是否重复。
删除冗余变量。
通过收集更多数据增加样本量。
预测变量标准化。
主成分分析、岭回归、最小二乘回归(均为数据降维的方法)。
主成分分析经常用于对数据的降维,通过选择具有较高方差的主成分来替代原始的数据。主成分分析的另一个主要用途是解决多重共线性问题。此外,通过仅对所有主成分的子集进行回归,主成分分析可以显著降低基础模型的参数数量。
假设最初的模型中有\(p\)个预测变量\(x_1,x_2...,x_p\),每个变量均有\(n\)条记录,则数据矩阵如下所示:
\[ D= \begin{pmatrix} x_{11} & x_{12} & \cdots & x_{1p} \\ x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{np} \\ \end{pmatrix} \]
通过主成分分析,将生成新的数据矩阵\(D^*\)(进行了如 Equation 2 的线性变换),拥有\(k(k<<p)\)个变量,每个变量同样拥有\(n\)条记录。值得注意的是,在生成新矩阵的过程中,实际是产生的一些新的变量的,主成分分析有助于识别数据变化最大的\(k\)个变量。
\[ \begin{pmatrix} U_1 \\ U_2 \\ \vdots \\ U_p \end{pmatrix} = \begin{pmatrix} a_{11} & \cdots & a_{1p} \\ a_{21} & \cdots & a_{2p} \\ \vdots & \ddots & \vdots \\ a_{n1} & \cdots & a_{np} \\ \end{pmatrix} \begin{pmatrix} X_1 \\ X_2 \\ \vdots \\ X_P \end{pmatrix} \tag{2}\]
假设原始模型中最初有\(p\)个预测变量,它们是\(X_1, X_2,...,X_P\)。
计算是\(X_1, X_2,...,X_P\)的方差—协方差矩阵或相关矩阵。
进行协方差针或相关阵的特征分析。
通过降低数量级对特征值进行排序,并将它们存储为一组排序的(特征值,特征向量)对。
计算主成分(Principal Component,PC)的解释方差比例及解释方差的累积和。
如果在最后一步中计算的累积和非常接近1,则仅选择第一个\(k\)特征值。这个\(k\)个PC足以捕获由原始变量生成的几乎相同量的可变性。
相应地提取所有\(k\)个特征向量,并且仅通过将它们从左到右并排保持来制作变换矩阵W。该变换矩阵的阶数为\(n×k\)。
最终通过计算以生成\(k\)阶数据矩阵。
当然以上步骤只是需要我们了解即可,在R中可以完全交给计算机来处理。
R语言的基础安装包就提供了主成分分析和因子分析的函数,分别为princomp()和factanal()。这里我们主要使用psych包中更丰富、提供更多选项的函数来进行主成分/因子分析,它们输出结果的形式也更具可读性。psych包中进行主成分/因子分析的函数如 表 1 所示。
| 函数 | 说明 | 备注 |
|---|---|---|
| principal() | 主成分分析 | 含多种可选的方差旋转方法 |
| fa() | 因子分析 | 可用主轴、最小残差、加权最小平方、最大似然估计 |
| fa.parallel() | 碎石图 | 包含平行分析 |
| factor.plot() | 主成分/因子分析结果图绘制 | |
| fa.diagram() | 主成分/因子分析荷载矩阵绘制 | |
| scree() | 主成分/因子分析碎石图 |
R中主成分/因子分析的常见步骤如下:
principal()和fa()函数时要确保输入的数据没有缺失值。主成分分析的目标是用一组较少的不相关变量代替大量相关变量,并尽可能保留初始变量的信息,这些推到所得的变量(即主成分)其实就是观测变量的线性组合。
我们使用USJudgeRatings数据集对R中主成分分析的步骤进行演示,该数据包含了律师对美国高等法院法官的评分,包含43个观测值(即43位律师)和12个变量(即律师对法官的评价指标)。
我们的目标是希望通过较少的复合变量来汇总除CONT外11个变量的评估信息,即简化数据,可以使用主成分分析。原始数据本身不存在缺失值,所以下一步是需要判断所需主成分的数量
判断主成分数量可遵循以下准则:
fa.parallel()函数同时展示library(psych)
fa.parallel(USJudgeRatings[, -1],
fa = "pc", n.iter = 100, show.legend = FALSE, main = NULL
)Parallel analysis suggests that the number of factors = NA and the number of components = 1 图 1 展示了:
3三种特征值均表明选择一个组成分即可保留数据集的绝大部分信息。下一步就该选择主成分了。
使用principal()函数提取主成分,基本形式为principal(r, nfactors, rotate, scores):
r为相关系数矩阵或原始数据矩阵nfactor为主成分数量rotate指定旋转方法,参看 Section 3
scores设定是否需要计算主成分得分(默认为不需要)pc <- principal(USJudgeRatings[, -1], nfactors = 1)
pcPrincipal Components Analysis
Call: principal(r = USJudgeRatings[, -1], nfactors = 1)
Standardized loadings (pattern matrix) based upon correlation matrix
PC1 h2 u2 com
INTG 0.92 0.84 0.1565 1
DMNR 0.91 0.83 0.1663 1
DILG 0.97 0.94 0.0613 1
CFMG 0.96 0.93 0.0720 1
DECI 0.96 0.92 0.0763 1
PREP 0.98 0.97 0.0299 1
FAMI 0.98 0.95 0.0469 1
ORAL 1.00 0.99 0.0091 1
WRIT 0.99 0.98 0.0196 1
PHYS 0.89 0.80 0.2013 1
RTEN 0.99 0.97 0.0275 1
PC1
SS loadings 10.13
Proportion Var 0.92
Mean item complexity = 1
Test of the hypothesis that 1 component is sufficient.
The root mean square of the residuals (RMSR) is 0.04
with the empirical chi square 6.21 with prob < 1
Fit based upon off diagonal values = 1