初步探索
library(maps)
op <- par(mar = c(0, 0, 0, 0))
map("state", projection = "polyconic")
map("county", projection = "polyconic")
par(op)
从图 图 1 可以看出,此地图数据缺少了阿拉斯加和夏威夷的数据。
此外,maps包内置的数据集county.flips记录了美国各郡县的行政代码及州郡名称;内置的unemp数据集记录了2009年美国各郡县的失业率。但这两个数据集的行数不同,后者大于前者。
'data.frame': 3085 obs. of 2 variables:
$ fips : int 1001 1003 1005 1007 1009 1011 1013 1015 1017 1019 ...
$ polyname: chr "alabama,autauga" "alabama,baldwin" "alabama,barbour" "alabama,bibb" ...
'data.frame': 3218 obs. of 3 variables:
$ fips : int 1001 1003 1005 1007 1009 1011 1013 1015 1017 1019 ...
$ pop : int 23288 81706 9703 8475 25306 3527 8884 52055 13726 11583 ...
$ unemp: num 9.7 9.1 13.4 12.1 9.9 16.4 16.7 10.8 18.6 11.8 ...
初步推测及处理思路:
- 相对失业率数据集
unemp 来说,美国州、郡县级地图数据不完整,各郡县 FIPS 代码数据集 county.fips 不完整。
- 相对
unemp数据,county.fips数据缺少了哪些地区:将两个数据集连接后,查看polyname列有哪些缺失值,即可得知缺少哪些郡县的代码。
- 进一步,我们统计各州缺失郡县代码的数量。
# 统计各州缺失代码数量-fips列前两个数字代表州,具体来说:
# 20-Kansas 堪萨斯州、21-Kentucky 肯塔基州、22-Louisiana 路易斯安那州、15-Hawaii 夏威夷州、51-Virginia 弗吉尼亚州、72-Puerto Rico 波多黎各(领地)
tmp2 <- tmp2 %>%
mutate(state_fips = str_sub(fips, start = 1, end = 2))
tmp2 %>%
group_by(state_fips) %>%
count()
# A tibble: 7 × 2
# Groups: state_fips [7]
state_fips n
<chr> <int>
1 15 4
2 20 8
3 21 10
4 22 9
5 46 1
6 51 34
7 72 78
值得注意的是,unemp和county.fips两个数据集均采用整数型来储存FIPS代码,但实际应该采用字符型来储存才合适。 本例中,没有关联上的州代码均在10以上,所以才能使用str_sub()函数进行代码抽取,否则需要另想办法。
数据探索
对于区域数据,描述其空间分布采用的常见图形是地区分布图(Choropleth maps)。也叫围栏图,一个个多边形围成的区域就好比大草原上的一个个围栏。也叫面量图,一块块区域加上该区域的属性、度量指标(经济的、人文的、社会的)。
一般初步探索我们会采用绘图的形式,图形可以直观的对数据进行展示。我们采用熟悉的ggplot2包进行绘图。
Simple feature collection with 3220 features and 9 fields
Geometry type: GEOMETRY
Dimension: XY
Bounding box: xmin: -3112200 ymin: -1697728 xmax: 2258154 ymax: 1558935
Projected CRS: USA_Contiguous_Albers_Equal_Area_Conic
First 10 features:
STATEFP COUNTYFP COUNTYNS AFFGEOID GEOID NAME LSAD ALAND
1 29 227 00758566 0500000US29227 29227 Worth 06 690564983
2 31 061 00835852 0500000US31061 31061 Franklin 06 1491355860
3 36 013 00974105 0500000US36013 36013 Chautauqua 06 2746047476
4 37 181 01008591 0500000US37181 37181 Vance 06 653713542
5 47 183 01639799 0500000US47183 47183 Weakley 06 1503107848
6 44 003 01219778 0500000US44003 44003 Kent 06 436581658
7 08 101 00198166 0500000US08101 08101 Pueblo 06 6179964847
8 17 175 00424288 0500000US17175 17175 Stark 06 746156170
9 29 169 00758539 0500000US29169 29169 Pulaski 06 1417013177
10 19 151 00465264 0500000US19151 19151 Pocahontas 06 1495047191
AWATER geometry
1 493903 MULTIPOLYGON (((114835.6 34...
2 487899 MULTIPOLYGON (((-267685.1 3...
3 1139407865 MULTIPOLYGON (((1324221 647...
4 42178610 MULTIPOLYGON (((1544260 322...
5 3707114 MULTIPOLYGON (((625934.5 -9...
6 50693232 MULTIPOLYGON (((1977965 726...
7 30219283 MULTIPOLYGON (((-783174.5 1...
8 684784 MULTIPOLYGON (((500559 4247...
9 11314125 MULTIPOLYGON (((312851.7 46...
10 3666530 MULTIPOLYGON (((88185.95 60...
# 地理区域唯一标识
us_county_map$GEOID <- as.integer(us_county_map$GEOID)
# 将失业率数据和地图数据合并
us_county_data <- us_county_map %>%
left_join(unemp, by = c("GEOID" = "fips"))
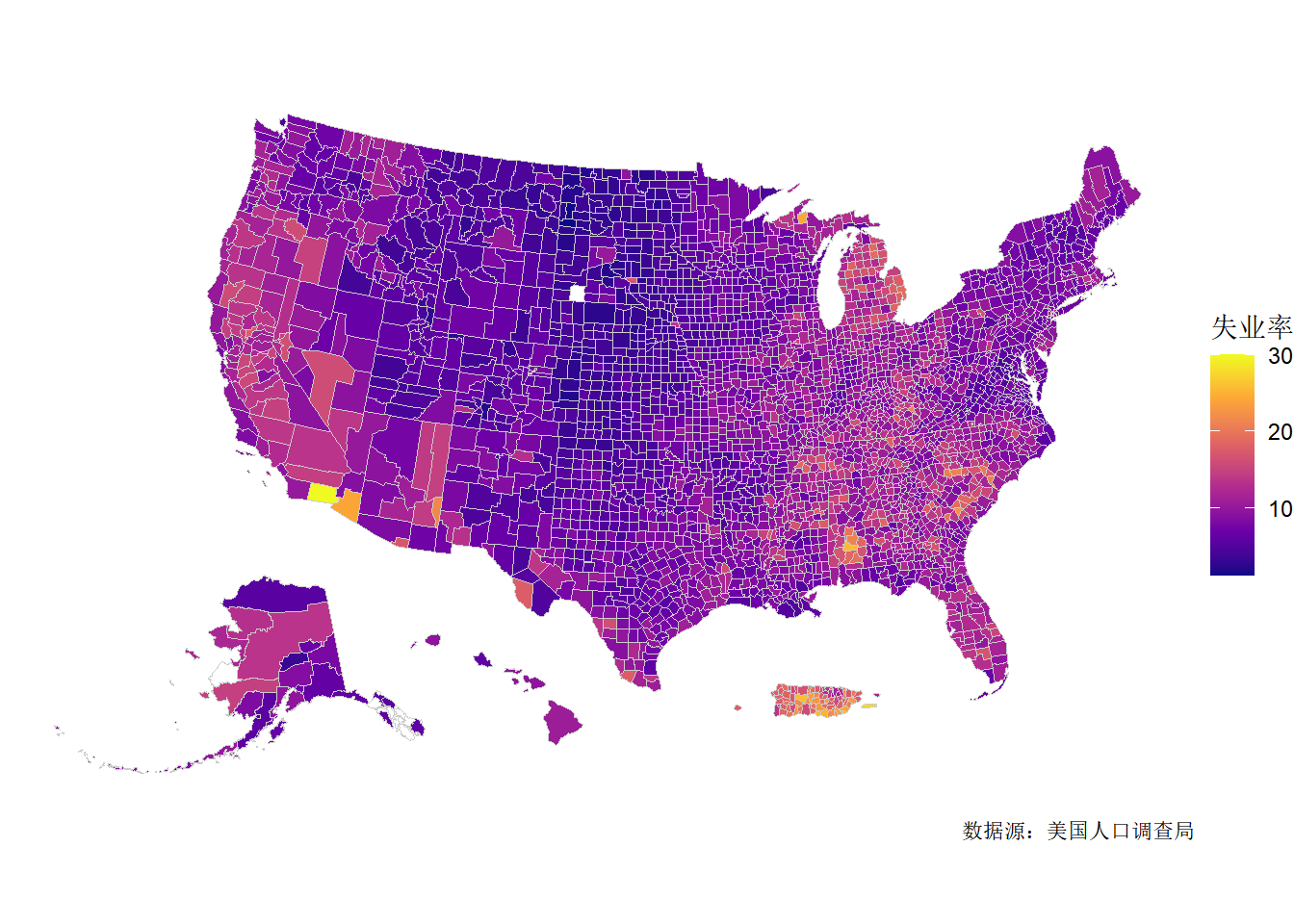
ggplot() +
geom_sf(
data = us_county_data, aes(fill = unemp),
colour = "grey80", linewidth = 0.05
) +
geom_sf(
data = us_state_map,
colour = "grey80", fill = NA, linewidth = 0.1
) +
scale_fill_viridis_c(
option = "plasma", na.value = "white"
) +
theme_void() +
labs(
fill = "失业率", caption = "数据源:美国人口调查局"
)
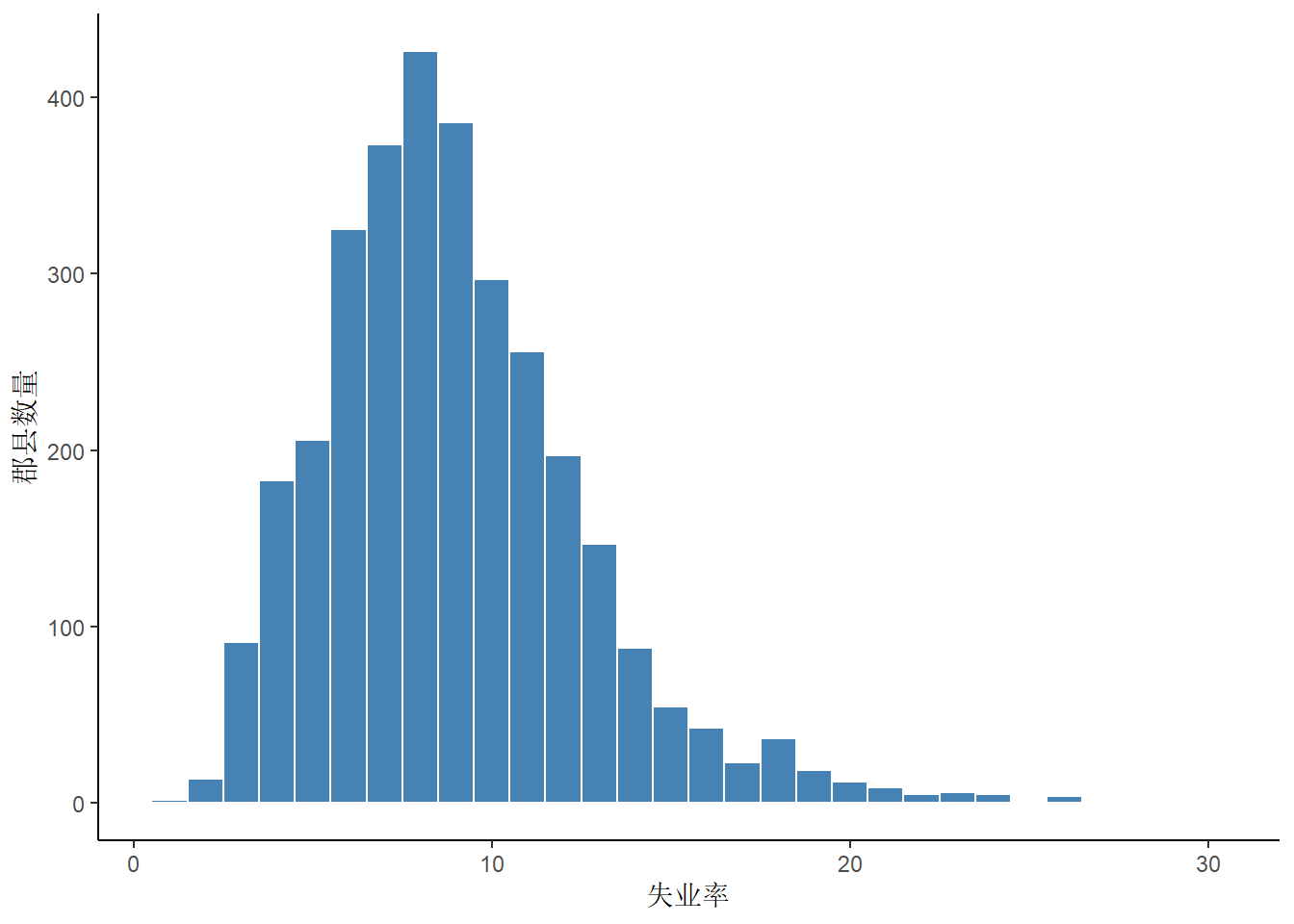
以一个百分点为间隔,统计美国各郡县的失业率分布情况
由 图 2 可知,除人口较多、经济较发达的郡县失业率远高于其他郡县,剩余的呈现正态分布的趋势,失业率集中于8%左右。
数据分析
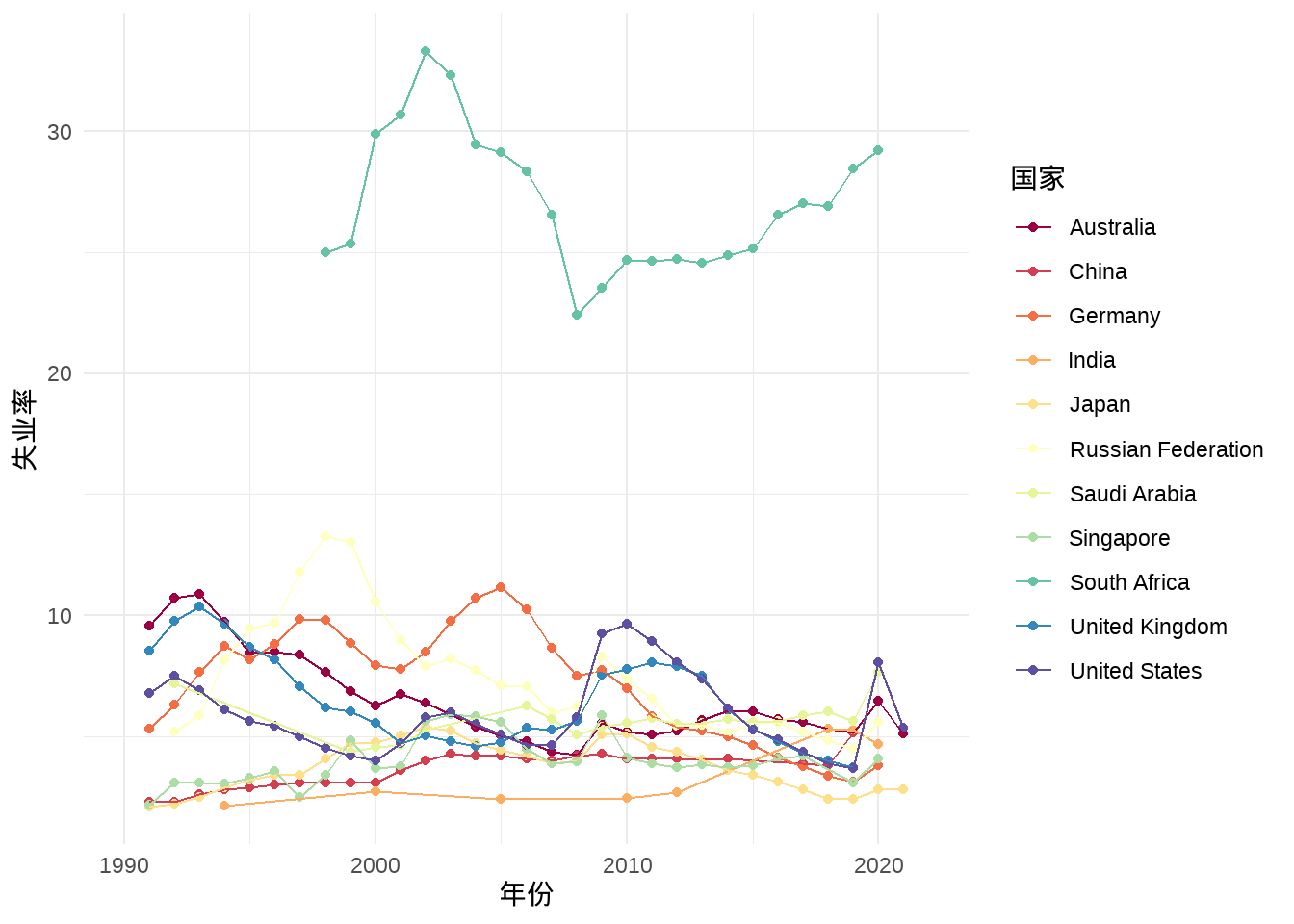
2019 年新冠疫情席卷全球,对全世界的经济造成不可估量的影响,对中国来说也不例外。2022 年 11 月 15 日至 16 日,二十国集团领导人第十七次峰会在印度尼西亚的巴厘岛举行,峰会主题为「共同复苏、强劲复苏」。G20 包含 中国、韩国、印度、美国、英国、加拿大、德国、意大利、法国、俄罗斯、日本、欧洲联盟、印度尼西亚、墨西哥、南非共和国、沙特阿拉伯、土耳其、澳大利亚、阿根廷、巴西。首先看看 G20 各个国家的整体失业率情况。
# 使用世界银行数据库获取最近30年宏观进行数据
wb_world_indicator <- wbstats::wb_data(
indicator = c(
"SL.UEM.TOTL", # 失业人数 Number of people unemployed
"SL.UEM.TOTL.ZS", # 失业率 Unemployed (%) (modeled ILO estimate)
"SL.UEM.TOTL.NE.ZS", # 失业率 Unemployed (%) national estimate
"NY.GDP.PCAP.KD.ZG", # 人均 GDP 增速
"NY.GDP.MKTP.CD", # GDP 总量
"NY.GDP.MKTP.KD.ZG", # GDP 增速
"FP.CPI.TOTL", # 消费价格指数(以 2010 年为对比基数 100)
"FP.CPI.TOTL.ZG", # 通货膨胀率
"SI.POV.GINI", # Gini 指数
"SP.DYN.LE00.IN", # 预期寿命
"NY.GDP.PCAP.CD", # 人均 GDP
"SP.POP.TOTL" # 人口总数
),
country = "countries_only",
return_wide = FALSE,
start_date = 1991, end_date = 2021
)
saveRDS(wb_world_indicator, file = "D:/Myblog/datas")
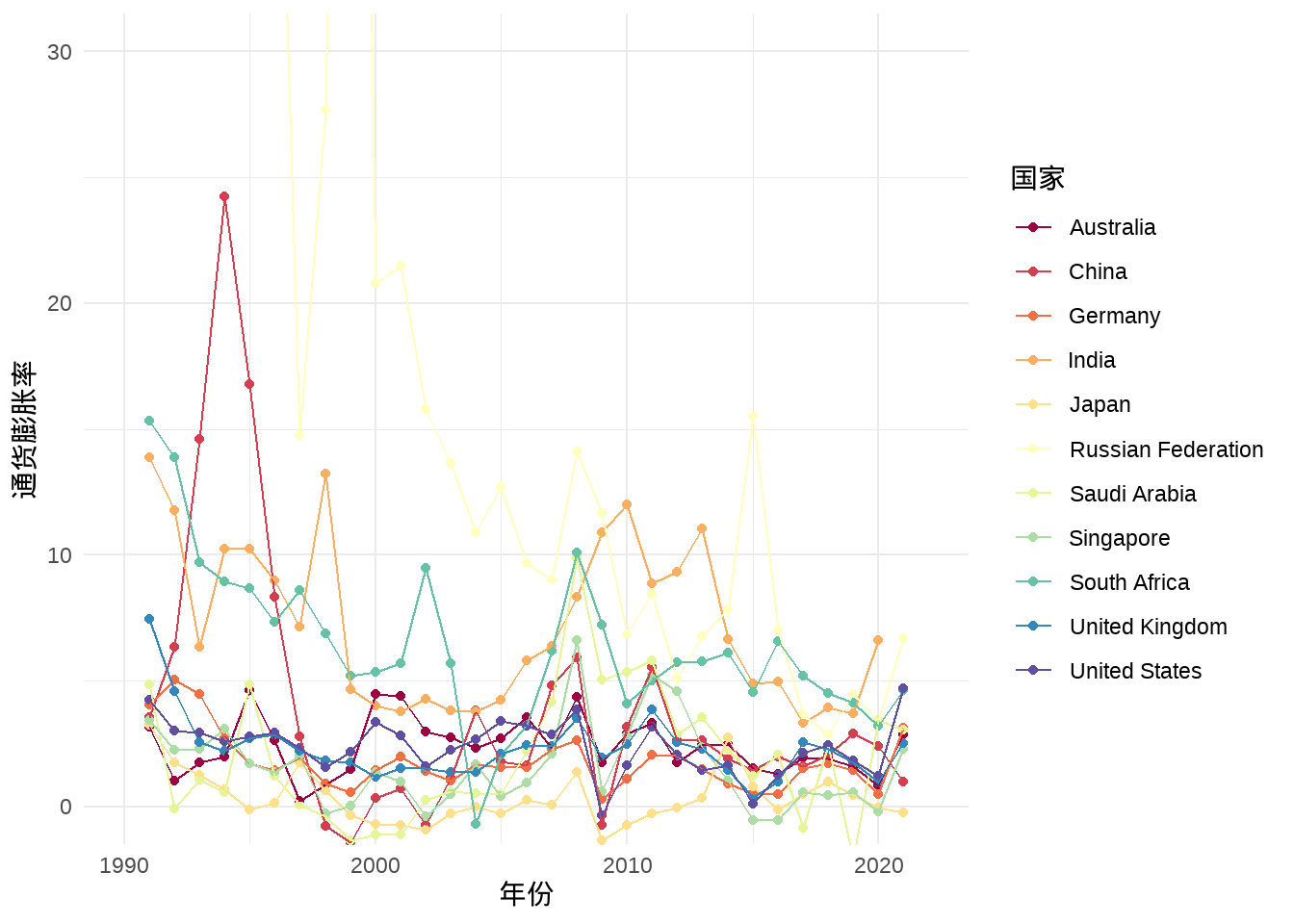
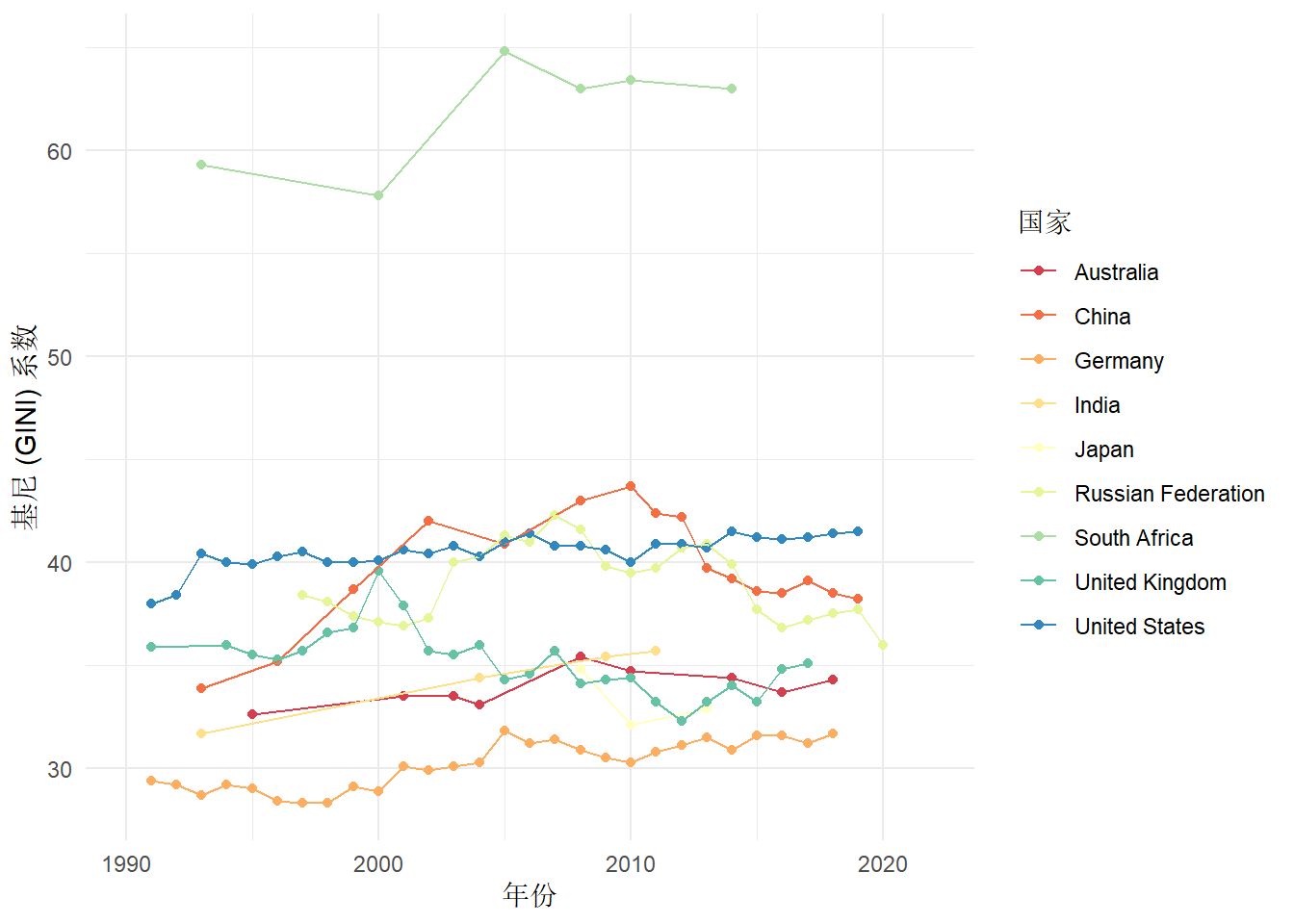
从G20中选取11个国家:中国、印度、美国、英国、德国、法国、俄罗斯、日本、南非共和国、沙特阿拉伯、澳大利亚,分别对比各国失业率、通货膨胀、基尼(GINI)系数数据三个维度数据的差别。
wb_world_indicator <- readRDS("D:/Myblog/datas/wb_world_indicator.rds")
wb_world_df <- wb_world_indicator %>%
filter(iso3c %in% c("CHN", "SAU", "USA", "AUS", "DEU", "IND", "JPN", "RUS", "ZAF", "SGP", "GBR")) %>%
filter(date >= 1991 & date <= 2021)
由 图 3 可知,除南非外,其他国家的失业率均在15%以下,且相对较为平稳。且2019年后,由于新冠疫情的影响,各国的失业率均有一定程度上涨。
从上图
基尼 (GINI) 系数数据不太多,南非有很高的基尼系数,贫富差距巨大,大部分在 30% - 40% 之间。中国贫富差距比美国小,比俄罗斯大,整体属于高位。
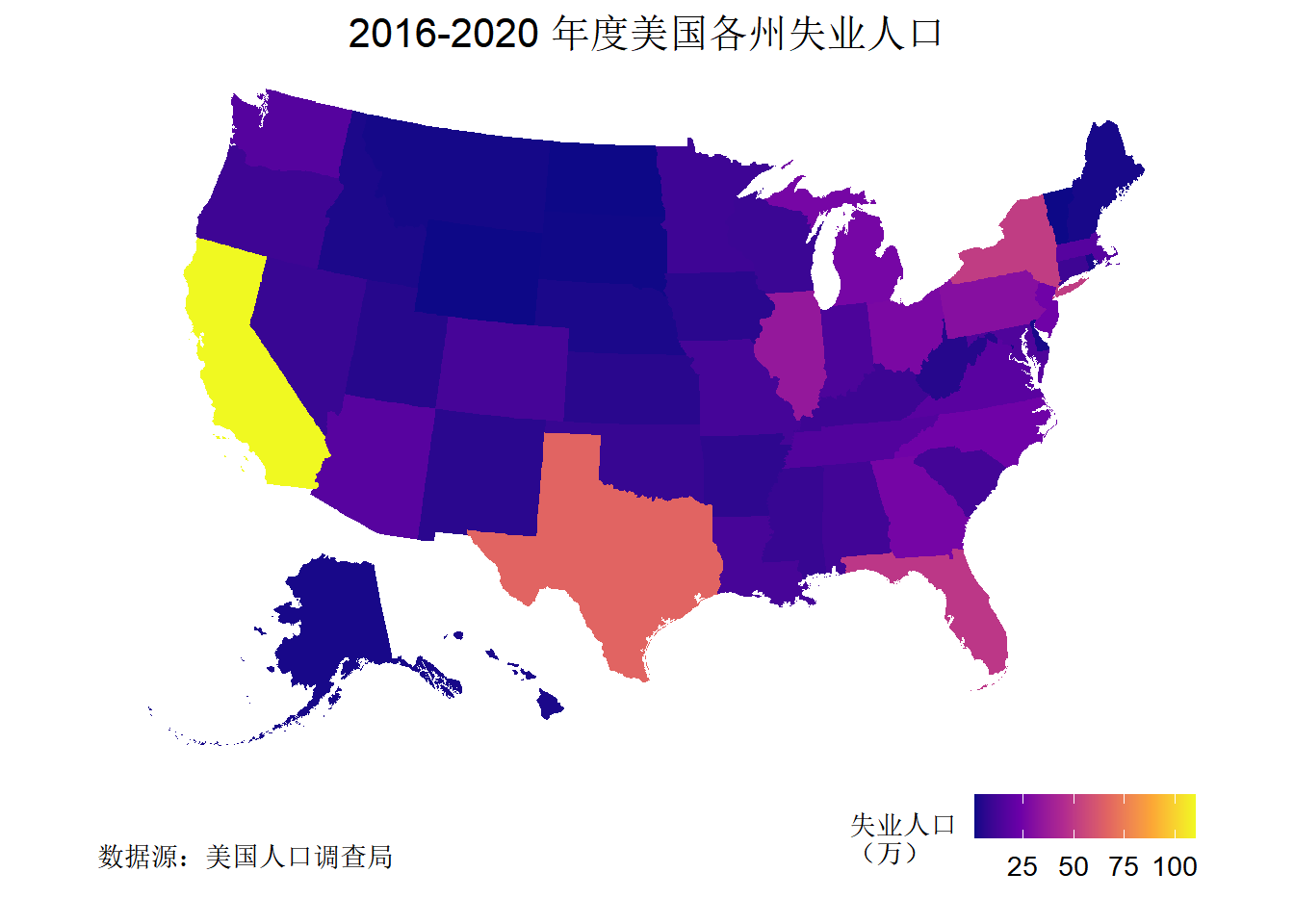
那么,美国各郡县的失业情况怎么样呢?
# 读取数据
us_unemp_county <- readRDS(file = "D:/Myblog/datas/us_unemp_county.rds")
us_unemp_state <- readRDS(file = "D:/Myblog/datas/us_unemp_state.rds")
# 绘图
ggplot() +
geom_sf(
data = us_unemp_state,
aes(fill = estimate / 10000), colour = NA
) +
scale_fill_viridis_c(option = "plasma", na.value = "grey80") +
coord_sf(crs = st_crs("ESRI:102003")) +
labs(
fill = "失业人口\n(万)",
title = "2016-2020 年度美国各州失业人口",
caption = "数据源:美国人口调查局"
) +
theme_void(base_size = 13) +
theme(
plot.title = element_text(hjust = 0.5),
legend.direction = "horizontal",
legend.position = "bottom",
legend.justification = "right",
legend.title = element_text(size = 10),
plot.caption = element_text(hjust = 0, vjust = 10)
)
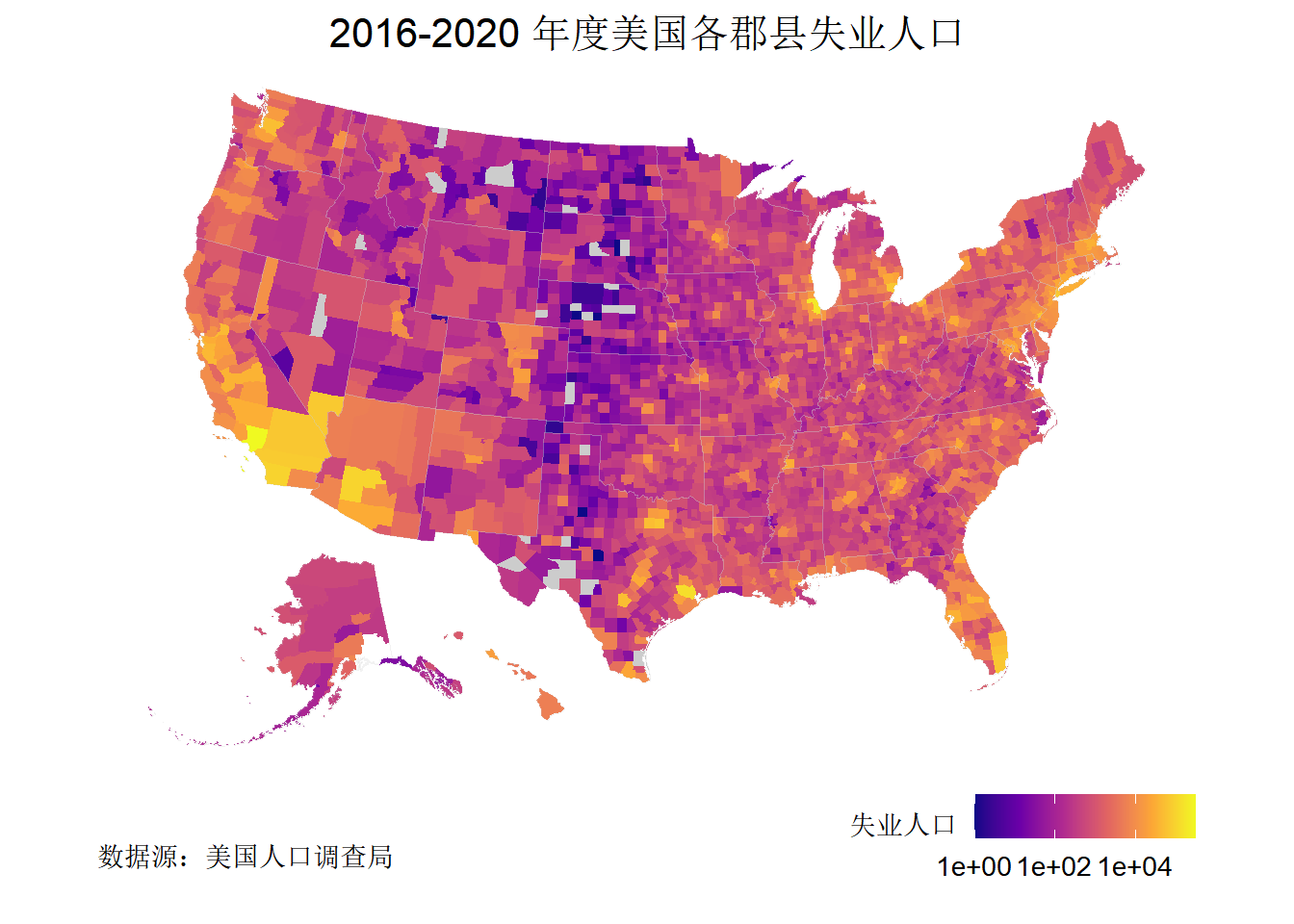
# 绘图
ggplot() +
geom_sf(
data = st_geometry(us_unemp_county), fill = "grey80", colour = NA
) +
geom_sf(
data = us_unemp_county[us_unemp_county$estimate > 0,],
aes(fill = estimate), colour = NA
) +
geom_sf(
data = us_unemp_state,
colour = alpha("gray80", 1 / 4), fill = NA, size = 0.15
) +
scale_fill_viridis_c(option = "plasma",
na.value = "grey80", trans = "log10") +
coord_sf(crs = st_crs("ESRI:102003")) +
labs(
fill = "失业人口\n",
title = "2016-2020 年度美国各郡县失业人口",
caption = "数据源:美国人口调查局"
) +
theme_void(base_size = 13) +
theme(
plot.title = element_text(hjust = 0.5),
legend.direction = "horizontal",
legend.position = "bottom",
legend.justification = "right",
legend.title = element_text(size = 10),
plot.caption = element_text(hjust = 0, vjust = 10)
)