library(tidyverse) # 加载tidyverse包,包含ggplot2等数据处理和可视化工具
library(patchwork) # 加载patchwork包,用于组合多个ggplot2图形
library(GGally) # 加载GGally包 ,扩展ggplot2功能,提供更多图形类型
library(broom) # 加载broom包,用于将统计模型结果转换为整洁的数据框
library(latex2exp) # 加载latex2exp包,用于将公式转换为LaTeX代码
weather_atl <- read_csv(
"D:/Myblog/posts/ggplot2-action-relationshipsplot-2024-07-03/tech/atl-weather-2019.csv"
)本文的重点是掌握双y轴的图形画法,这类图形在数据分析中会经常用到。
1 载入并清洗数据
2 绘制双 y 轴关系图
当两个不同的刻度测量的是同一件事,比如计数和百分比、华氏和摄氏、磅和千克、英寸和厘米等,绘制双y轴关系图往往是非常有用的。
绘制双y轴关系图的基本思路是,将两个变量分别放在两个y轴上,并在同一坐标系上绘制散点图。在ggplot2中,我们可以使用scale_y_continuous()函数来设置两个y轴的范围和刻度:
- 第二个y轴的范围和刻度可以通过
sec.axis参数来设置。 -
sec.axis参数会使用一个与其基本同名的函数,即sec_axis()来告诉ggplot2如何对第二y轴的刻度进行转换。 - 我们需要在
sec_axis()函数中指定一个公式或函数来定义如何将第一个y轴的值转换为第二个y轴的值,同时使用.符号来代替原始坐标轴的原始值(即第一个y轴的值)。
在
ggplot2中,参数的名称通常用.分割,而函数名则用_分割。例如,axis.text.x参数和element_text()函数。在weather_atl数据集中,温度的单位为华氏温度,通常情况下,我们希望将其转换为摄氏温度,它们之间具体的转换关系如下 Equation 1 所示。
\[ C = (32-F) \times -{\frac{5}{9}} \tag{1}\]
# 绘制双y轴关系图
ggplot(weather_atl, aes(x = time, y = temperatureHigh)) +
geom_line() + # 绘制第一个y轴的曲线
scale_y_continuous(
sec.axis = sec_axis(
# 设置第二个y轴的刻度
transform = ~ (32 - .) * -5 / 9,
# 设置第二个y轴的名称
name = "Celsius"
)
) +
labs(
x = NULL,
y = "Temperature (F)"
) +
theme_minimal()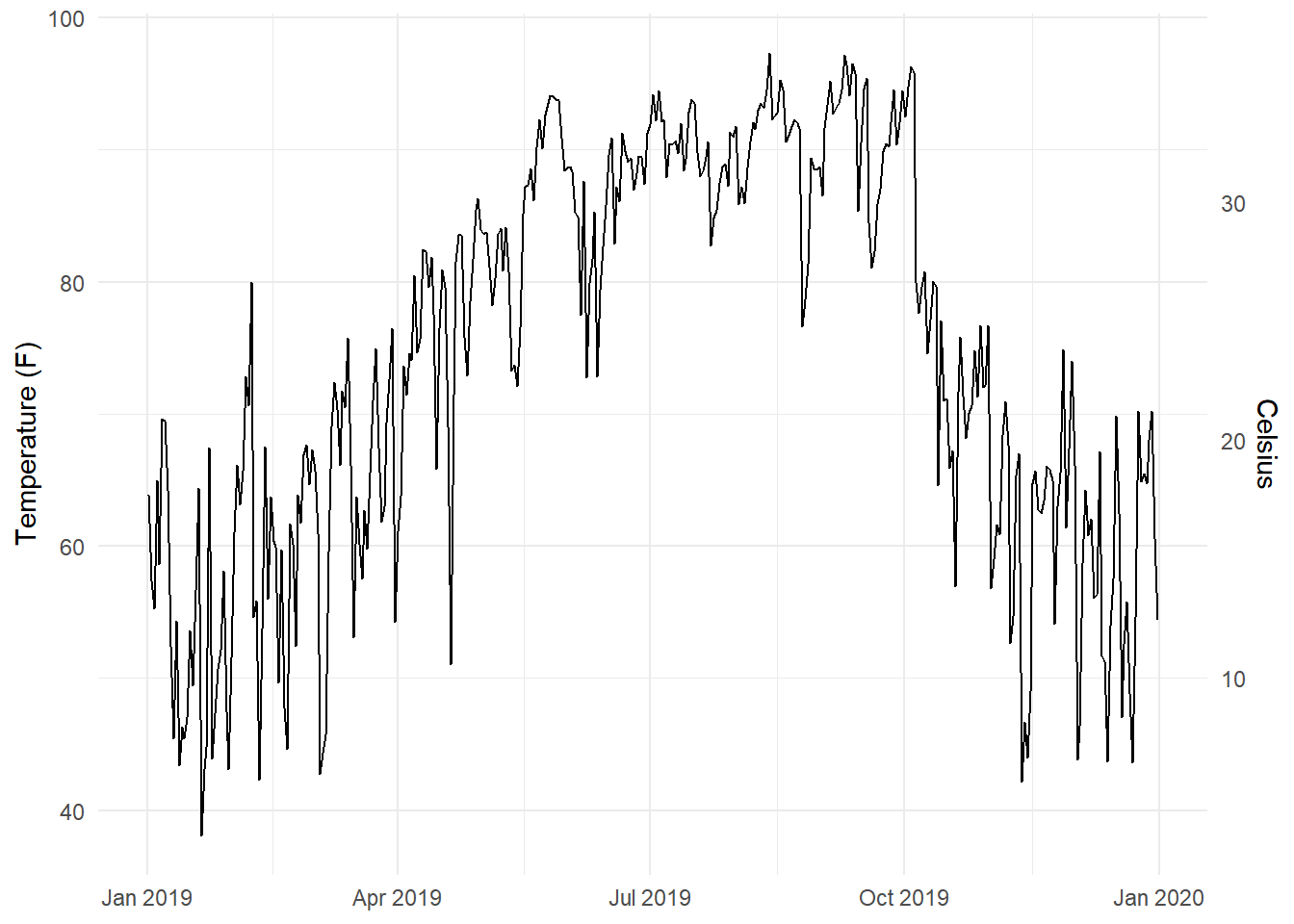
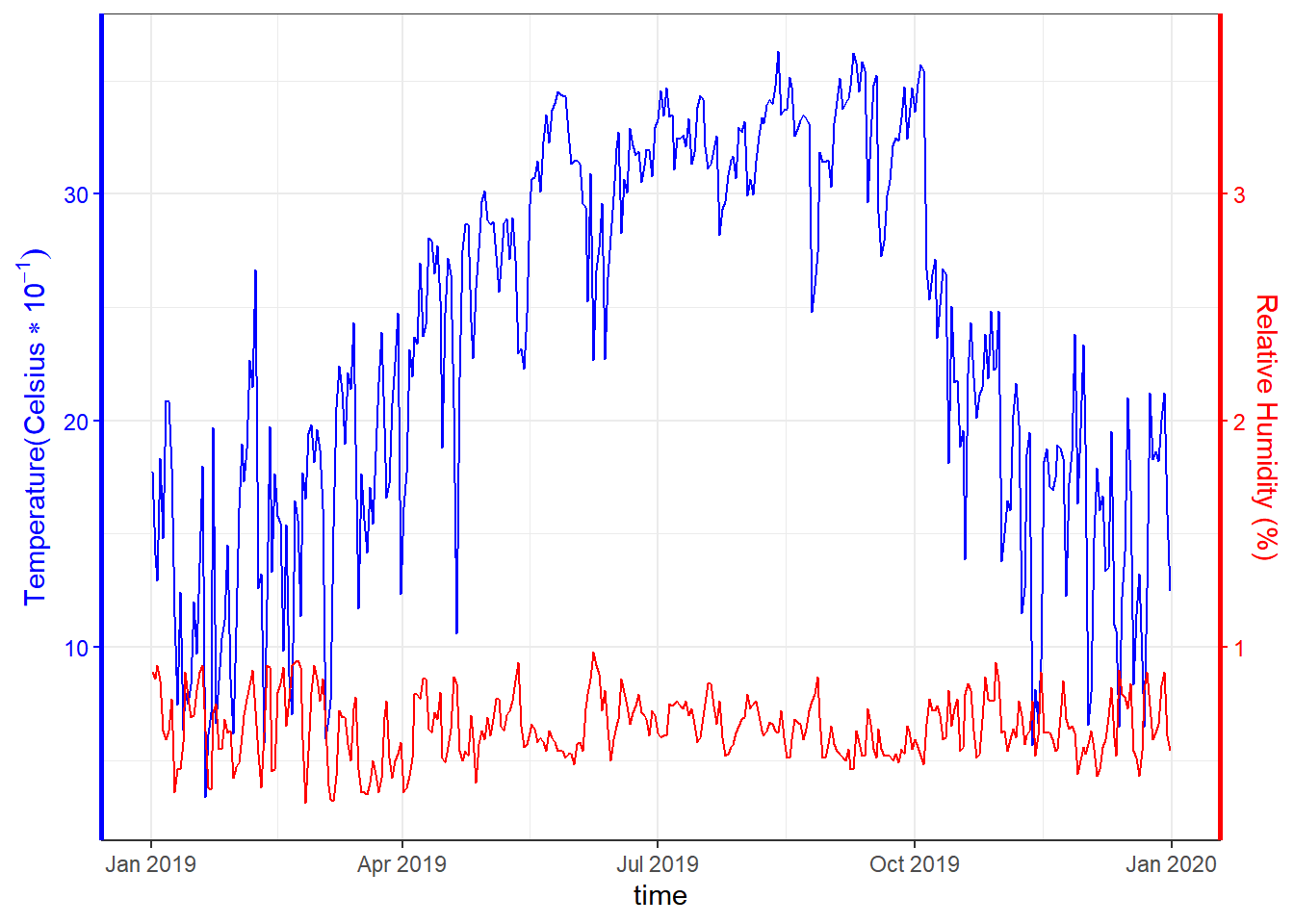
2.1 绘制双y轴双图形
在双y轴的基础上,我们还可以绘制双图形,比如散点图和折线图结合。同样需要借助sec.axis参数
例如,我们想知道亚特兰大温度与湿度间的对比关系,其中:
- 第一y轴表示温度,用折线图展示。
- 第二y轴表示湿度,用折线图展示。
weather_atl %>%
mutate(temperatureHigh_C = ((32 - temperatureHigh) * -5 / 9)) %>%
ggplot(aes(x = time)) +
geom_line(aes(y = temperatureHigh_C), color = "blue") +
geom_line(aes(y = humidity * 10), color = "red") +
scale_y_continuous(
sec.axis = sec_axis(
transform = ~ . / 10,
name = "Relative Humidity (%)"
)
) +
theme_bw() +
labs(
y = TeX("Temperature($\\Celsius*10^{-1})$"),
) +
theme(
axis.title.y.left = element_text(color = "blue"),
axis.text.y.left = element_text(color = "blue"),
axis.ticks.y.left = element_line(color = "blue"),
axis.line.y.left = element_line(color = "blue", size = 1),
axis.title.y.right = element_text(color = "red"),
axis.text.y.right = element_text(color = "red"),
axis.ticks.y.right = element_line(color = "red"),
axis.line.y.right = element_line(color = "red", size = 1)
)
3 相关性图
3.1 散点阵图
使用GGally::ggpairs()函数可以绘制散点阵图。例如,高温和低温、湿度、风速和降水概率之间的相关性如何?我们首先用这些列制作一个较小的数据集,然后将该数据集输入 ggpairs() 查看所有相关信息:
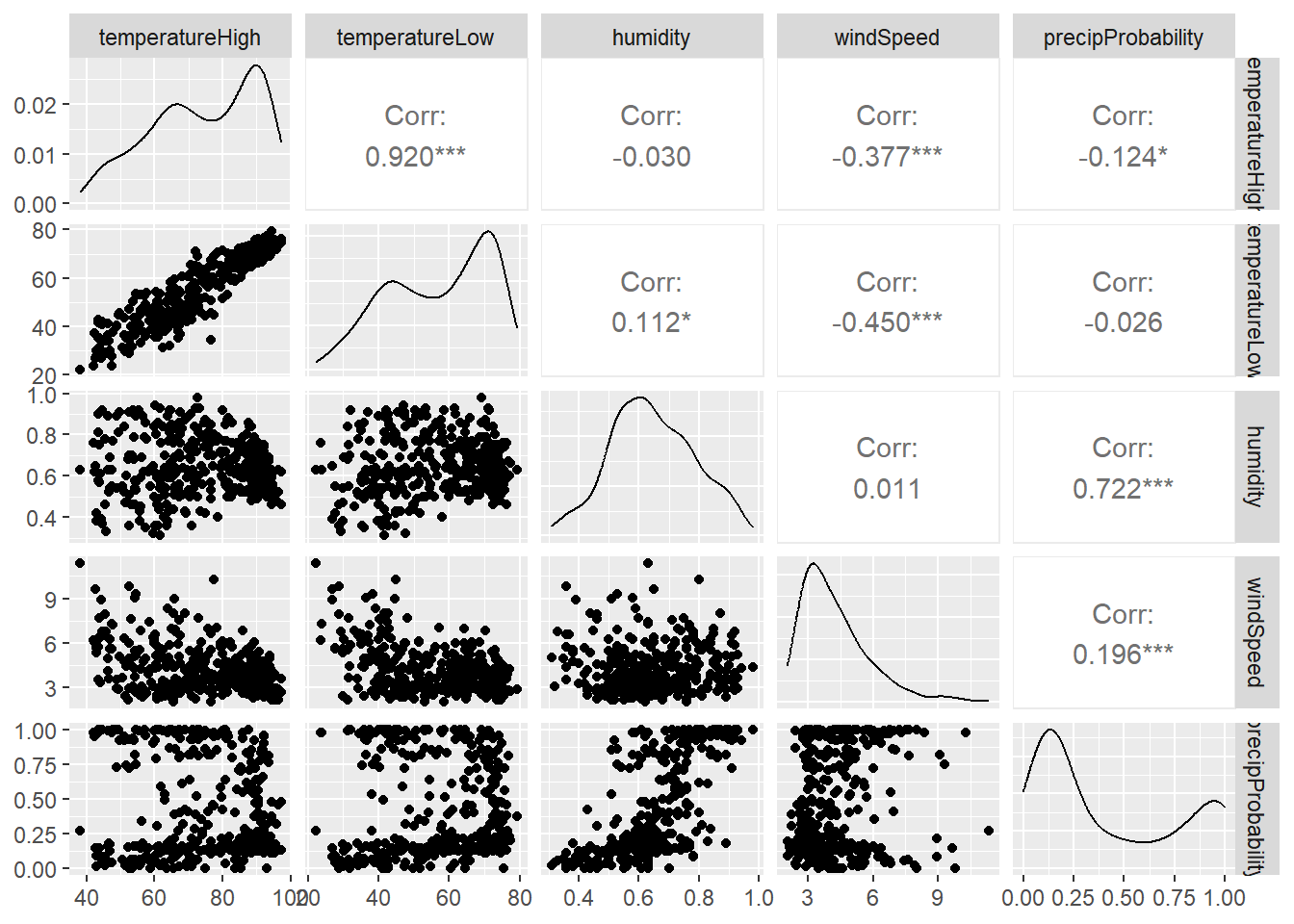
3.2 相关图-Correlograms
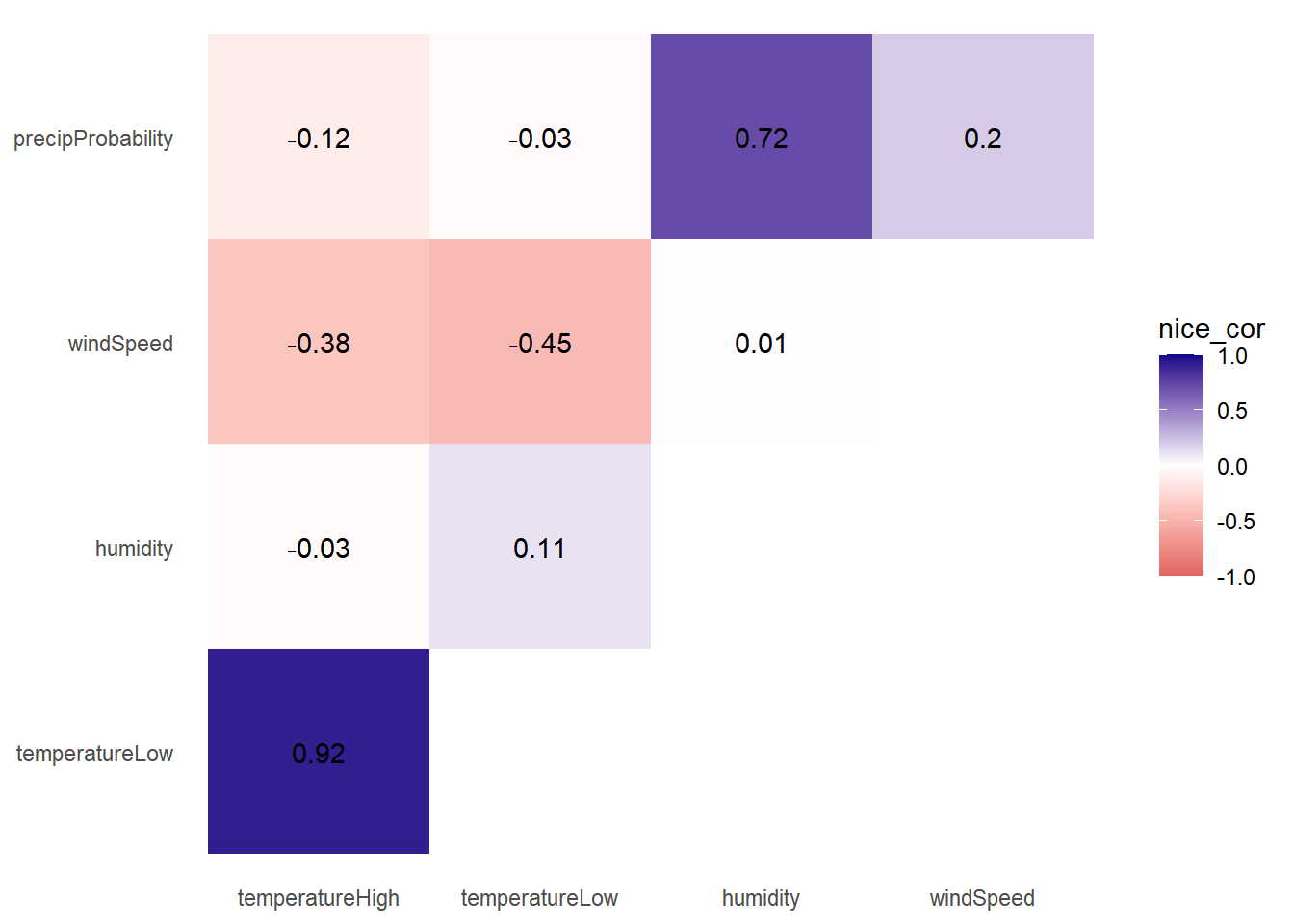
散点图矩阵通常包含过多信息,无法在实际出版物中使用。我在做自己的分析时会用到散点图矩阵,只是想看看不同变量之间的关系,但我很少把它们润色后公开发表,即我们熟悉的热图(heatmap)。
- 建立关心的主要变量的相关性矩阵。
- 该矩阵的两半(沿对角线分割)是相同的,因此我们可以用这段代码删除下三角(将下三角中的所有单元格设置为 NA )(可选操作)。
- 对相关矩阵数据表进行清洗整理。为了绘制图表,数据需要采用
Tidy(或长)的格式。以things_to_correlate行列名称添加一列,将所有列放入名为 measure1 的一列中,并将所有相关系数放入名为cor的一列中。 最后,我们确保测量变量按其出现顺序排列(否则,它们将按字母顺序绘制,不会形成三角形) - 绘制热图。
# 建立关心的主要变量的相关性矩阵
things_to_corr <- weather_atl %>%
select(
temperatureHigh, temperatureLow, humidity, windSpeed, precipProbability
) %>%
cor() %>%
as.data.frame()
# 删除下三角
things_to_corr[lower.tri(things_to_corr)] <- NA
# 数据整理
things_to_corr_tidy <- things_to_corr %>%
as.data.frame() %>% # 将数据转换为数据框
rownames_to_column("measure2") %>% # 将行名转换为列
# 将数据转换为长格式
pivot_longer(
-measure2,
names_to = "measure1",
values_to = "cor"
) %>%
# 将相关系数四舍五入到小数点后两位
mutate(nice_cor = round(cor, 2)) %>%
# 过滤掉measure1和measure2相同的数据
filter(measure1 != measure2) %>%
# 过滤掉相关系数为NA的数据
filter(!is.na(cor)) %>%
# 将measure1和measure2转换为有序因子
mutate(
measure1 = fct_inorder(measure1),
measure2 = fct_inorder(measure2)
)
# 绘制热图
ggplot(
things_to_corr_tidy,
aes(x = measure2, y = measure1, fill = nice_cor)
) +
geom_tile() +
geom_text(aes(label = nice_cor)) +
scale_fill_gradient2(
low = "#E16462", mid = "white", high = "#0D0887",
limits = c(-1, 1)
) +
labs(x = NULL, y = NULL) +
theme_minimal() +
theme(
panel.grid = element_blank()
)
4 系数图-Coefficient Plot
如果我们在模型中使用多个变量,就很难直观地看到结果,因为我们要处理多个维度。相反,我们可以使用系数图来查看模型中的各个系数。
4.1 建立相对复杂的模型
weather_atl_summer <- weather_atl %>%
filter(time >= "2019-05-01", time <= "2019-09-30") %>%
mutate(
humidity_scaled = humidity * 100,
moonPhase_scaled = moonPhase * 100,
precipProbability_scaled = precipProbability * 100,
cloudCover_scaled = cloudCover * 100
)
model_complex <- lm(
temperatureHigh ~ humidity_scaled + moonPhase_scaled +
precipProbability_scaled + windSpeed + pressure + cloudCover_scaled,
data = weather_atl_summer
)
tidy(model_complex, conf.int = TRUE)# A tibble: 7 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 265. 126. 2.11 3.66e-2 16.7 514.
2 humidity_scaled -0.111 0.0759 -1.47 1.44e-1 -0.261 0.0387
3 moonPhase_scaled 0.0124 0.0128 0.965 3.36e-1 -0.0129 0.0377
4 precipProbability_sca… 0.0358 0.0204 1.75 8.16e-2 -0.00454 0.0761
5 windSpeed -1.76 0.417 -4.22 4.30e-5 -2.58 -0.936
6 pressure -0.160 0.123 -1.30 1.96e-1 -0.403 0.0834
7 cloudCover_scaled -0.0950 0.0304 -3.12 2.17e-3 -0.155 -0.03494.2 解释系数
- 在其他条件不变的情况下,湿度每增加1%,最高气温平均下降0.11°,但这种影响在统计上并不显著。
- 在其他条件不变的情况下,月球能见度每增加1%,最高气温平均就会上升0.01°,而且这种影响在统计上并不显著。
- 在其他条件不变的情况下,降水概率每增加1%,平均最高气温就会上升0.04°,而且这种影响在统计上并不显著。
- 在其他条件不变的情况下,风速每增加1英里/小时,最高气温平均下降1.8°,而且这种影响在统计学上非常显著。
- 在其他条件不变的情况下,气压每增加1个单位,高温平均下降0.15°,而且这种影响在统计上并不显著。
- 在其他条件不变的情况下,云量每增加1%,最高气温平均会下降0.01°,而且这种影响在统计学上非常显著。
-
Intercept:截距,表示模型的预测值与实际值的差距。本模型中,截距非常无用,它显示当湿度为0%、看不见月亮、无降水机会、无风、无气压、无云层时,预测温度为 262°。
4.3 系数图
# 将模型结果转换为数据框
model_complex_tidy <- broom::tidy(model_complex, conf.int = TRUE) %>%
filter(term != "(Intercept)")
# 绘制系数图
ggplot(model_complex_tidy, aes(x = estimate, y = term)) +
geom_pointrange(aes(xmin = conf.low, xmax = conf.high)) +
geom_vline(xintercept = 0, color = "red", linetype = "dotted") +
labs(x = "Coefficient Estimate", y = NULL) +
theme_minimal()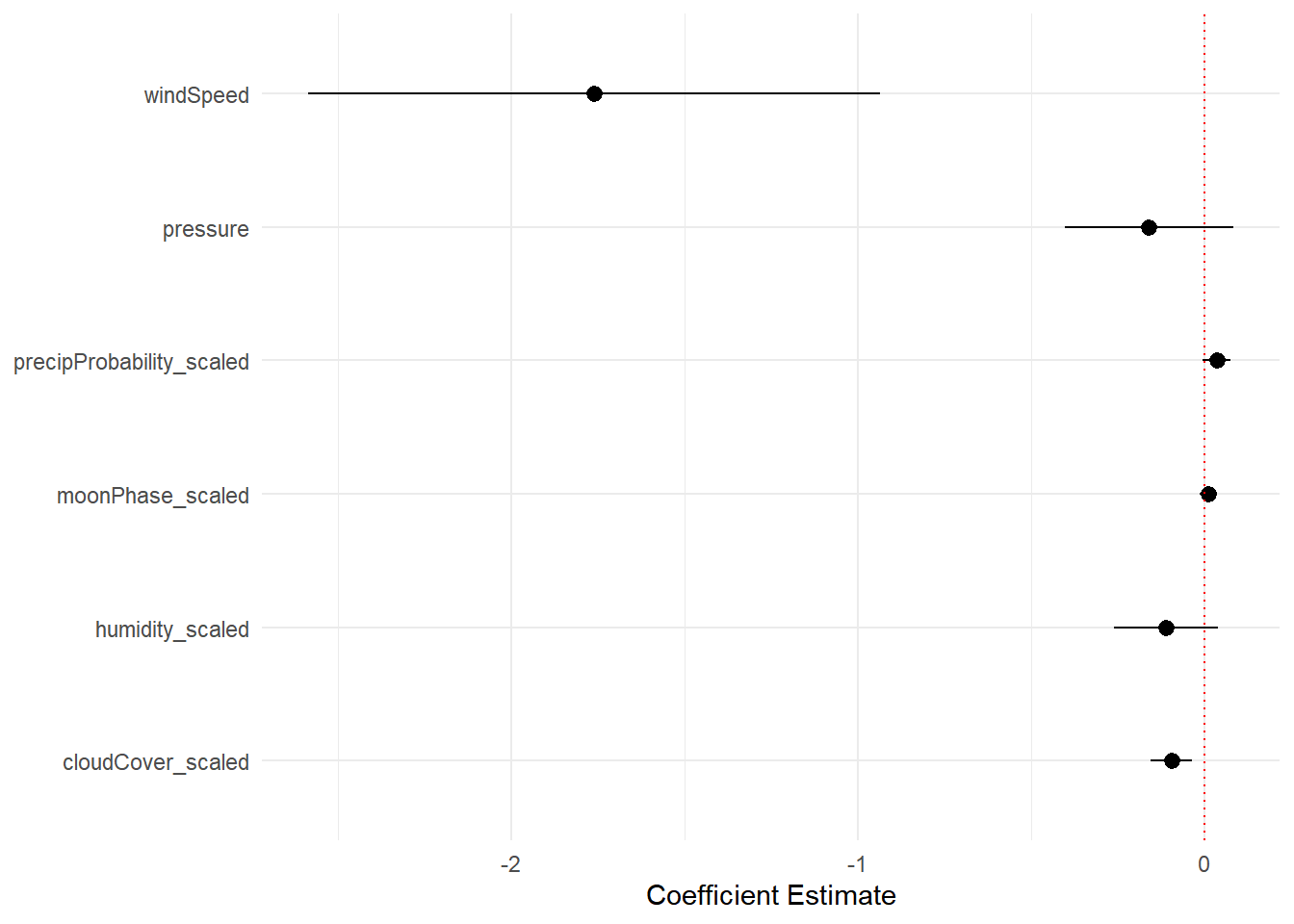
图 1 显示出模型各系数的估计值和置信区间,以及它们有多接近0。可以看出,风速(windSpeed)对温度的影响很大,其他系数均非常接近于0。