1 前言
从变量映射到视觉元素,是图形语法中非常重要的概念。
比如geom_point(mapping = aes(x = mass, y = height))是绘制散点图,x轴为mass变量,y轴为height变量。
因为geom_*()很强大而且也很容易理解,所以一般我们不会去思考我们的数据在喂给ggplot()后发生了什么,只希望能出图就行了。但实际上,ggplot()中其实进行了进一步的处理的,其实就是stat_**()系列函数。
2 什么要使用统计图层?
我们都知道,ggplot2绘制图形需要数据是tidy的,那么如果数据已经是tidy了,还需要使用stat_**()函数吗?
答案是有必要,因为即使数据是tidy的,图形显示出的也未必是我们想要的值。我们看一个例子:
simple_df <- tibble(
group = factor(rep(c("A", "B"), each = 15)),
subject = 1:30,
score = c(rnorm(15, 40, 20), rnorm(15, 60, 10))
)
simple_df# A tibble: 30 × 3
group subject score
<fct> <int> <dbl>
1 A 1 58.2
2 A 2 -6.94
3 A 3 35.2
4 A 4 17.8
5 A 5 35.4
6 A 6 62.4
7 A 7 41.7
8 A 8 59.6
9 A 9 40.5
10 A 10 54.6
# ℹ 20 more rows针对simple_df话柱形图,每个柱子代表一组group,柱子的高度则代表每组score的均值,怎么画?通常的想法,首先规整(tidy)数据,并且确保数据包含每个geom所需的美学映射,最后传递给ggplot()。
simple_df %>%
group_by(group) %>%
summarise(mean_score = mean(score)) %>%
ggplot(aes(x = group, y = mean_score)) +
geom_col()
如果想画误差棒呢?
simple_df %>%
group_by(group) %>%
summarise(
mean_score = mean(score),
se = sqrt(var(score) / length(score))
) %>%
mutate(
lower = mean_score - se,
upper = mean_score + se
) %>%
ggplot(aes(group, mean_score, ymin = lower, ymax = upper)) +
geom_errorbar()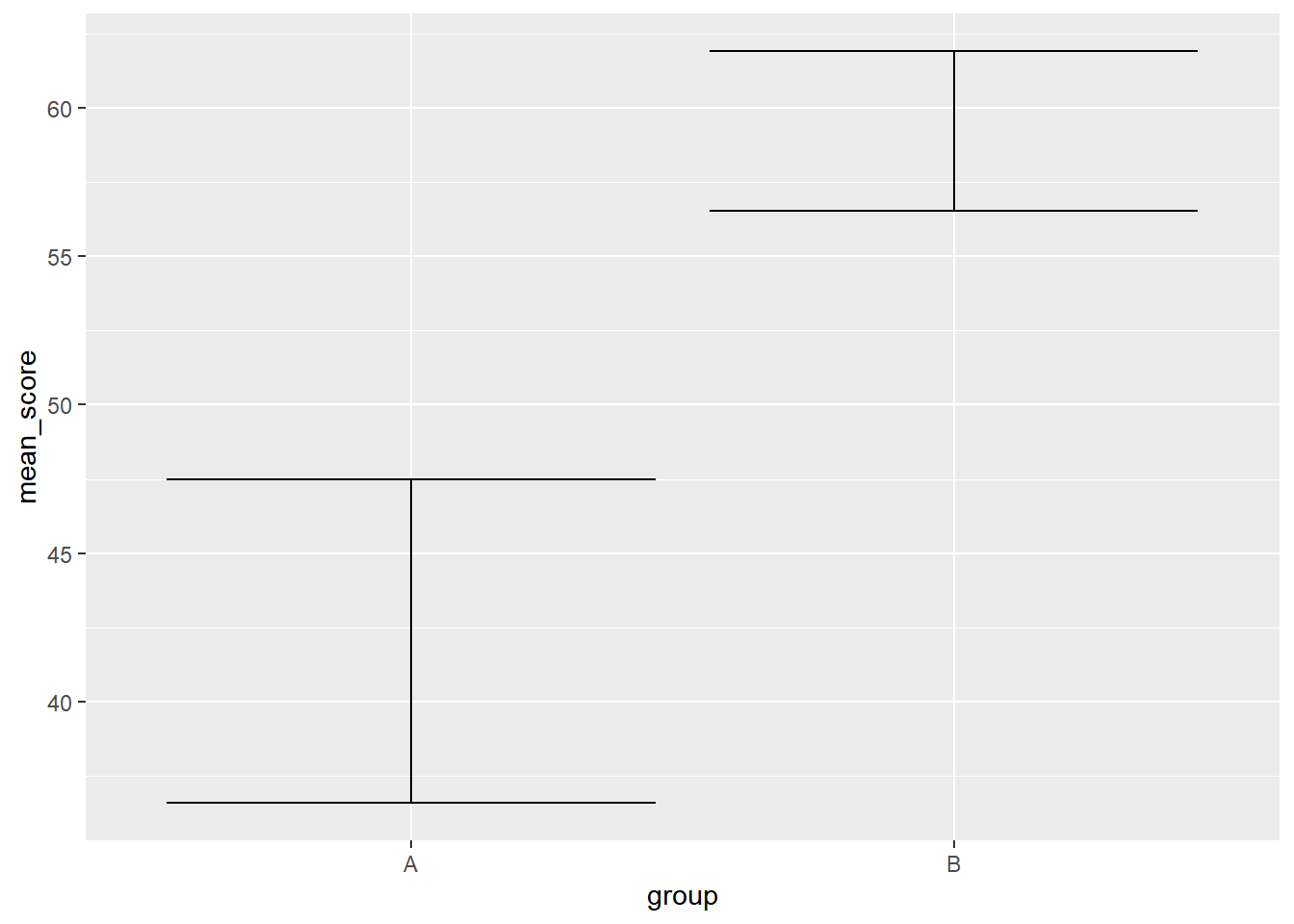
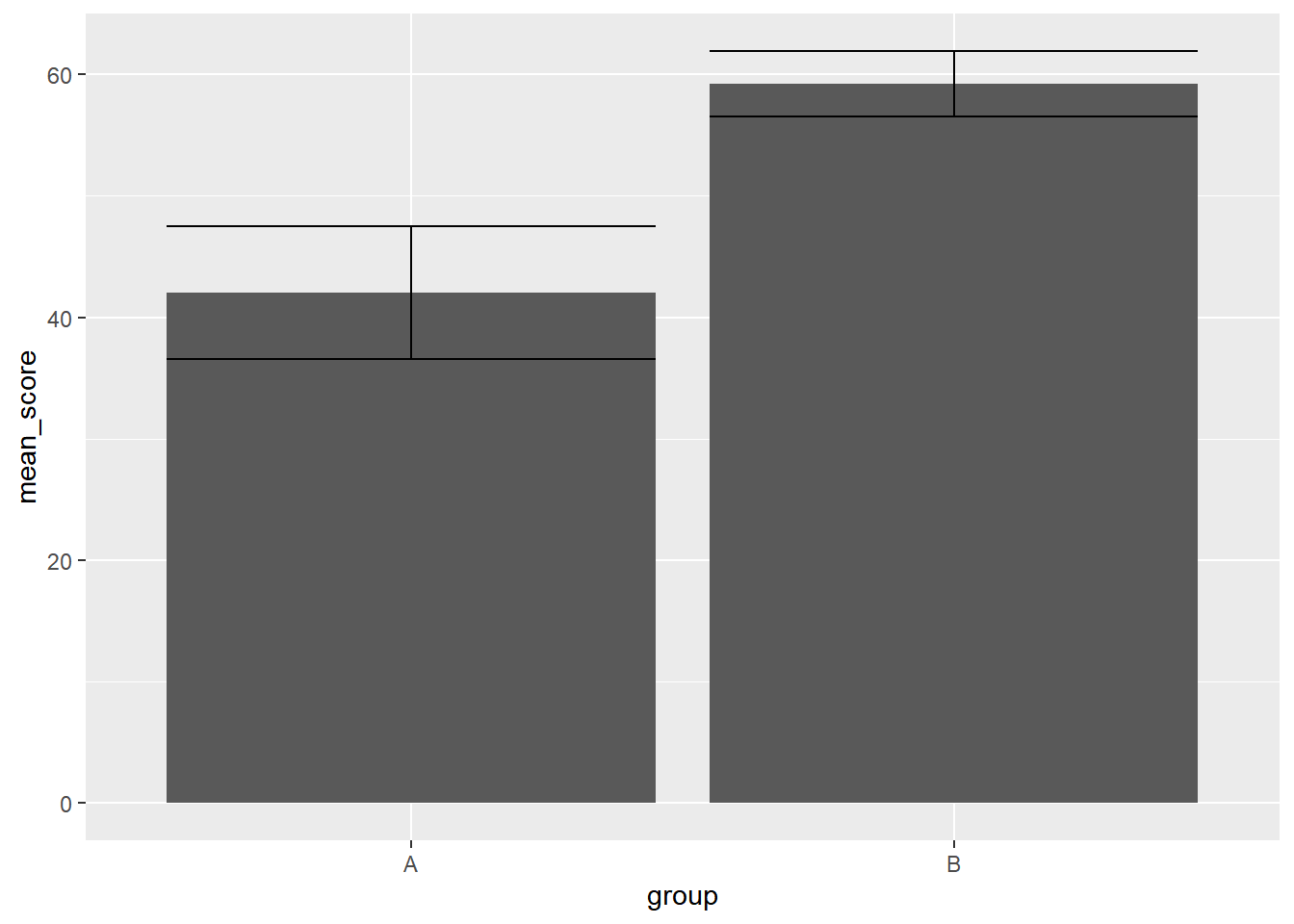
如果希望将误差棒和柱形图花在一个图上呢?
simple_df_bar <- simple_df %>%
group_by(group) %>%
summarize(
mean_score = mean(score),
.groups = "drop"
)
simple_df_errorbar <- simple_df %>%
group_by(group) %>%
summarize(
mean_score = mean(score),
se = sqrt(var(score) / length(score)),
.groups = "drop"
) %>%
mutate(
lower = mean_score - se,
upper = mean_score + se
)
ggplot() +
geom_col(
aes(x = group, y = mean_score),
data = simple_df_bar
) +
geom_errorbar(
aes(x = group, y = mean_score, ymin = lower, ymax = upper),
data = simple_df_errorbar
)
好像有点太长了!原因在于,我们认为在使用ggplot2画图时,一定要准备好一个tidy的数据,并把所有想画的几何形状,都整理至这个tidy数据中。
事实上,理论上讲,simple_data_bar 和 simple_data_errorbar 并不是真正的tidy格式。因为按照Hadley Wickham的对tidy的定义是,一行代表一次观察。 而这里的柱子的高度以及误差棒的两端不是观察出来的,而是统计计算出来的。
实际上,simple_data_bar 和 simple_data_errorbar都是来源于原始数据simple_df,那么我们为什么不直接把simple_df传递给ggplot(),让数据在内部转换,从而得到所需的美学映射呢?
simple_df %>%
ggplot(aes(x = group, y = score)) +
stat_summary(geom = "bar") +
stat_summary(geom = "errorbar")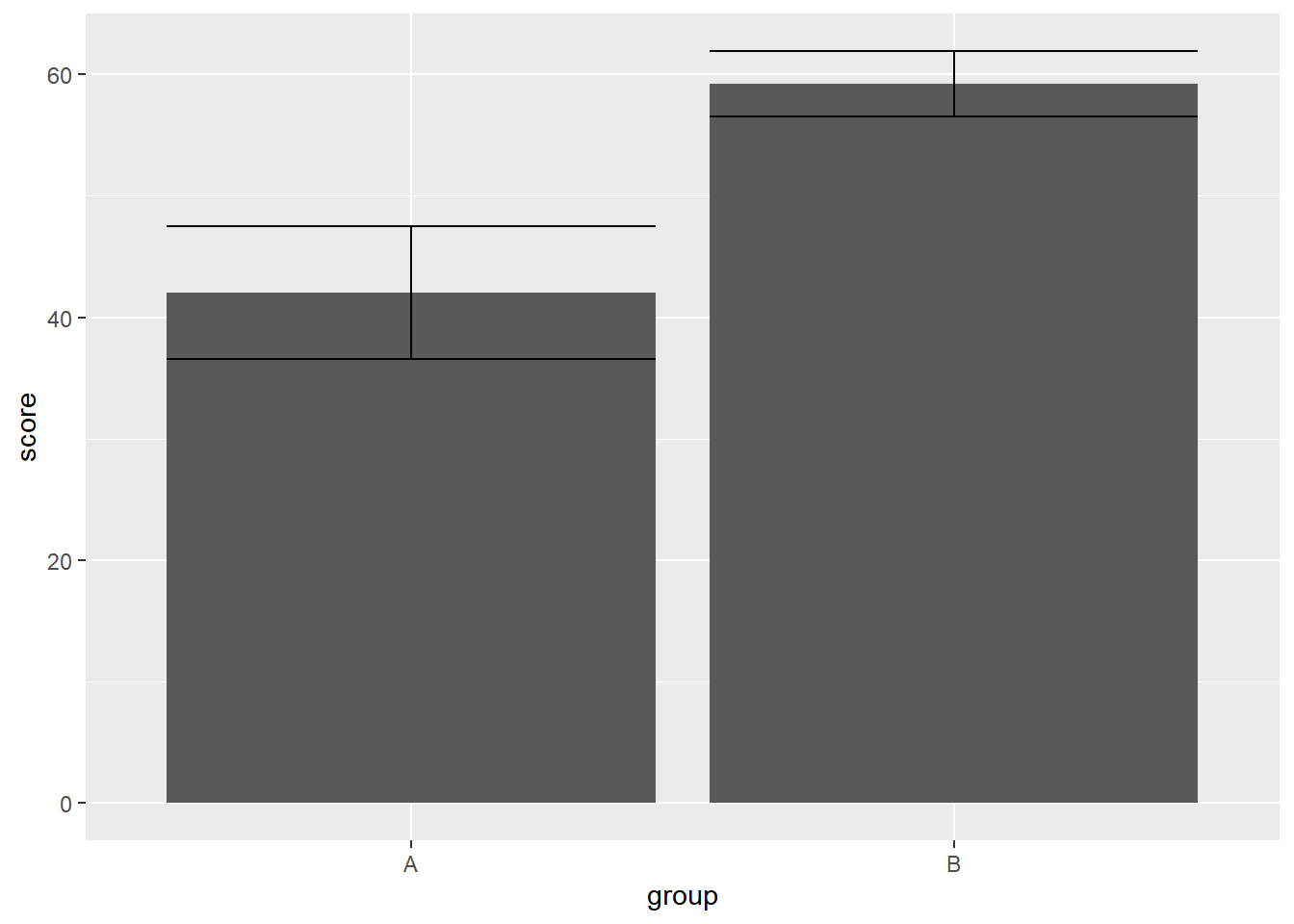
3 用stat_summary()理解统计图层
实际上,stat_summary() 是在数据可视化中最常用的一个函数,也是学习和理解 stat_*() 很好的例子,理解了stat_summary()的工作原理,其它的stat_*()也就都明白了。
# A tibble: 30 × 2
group height
<chr> <dbl>
1 A 179.
2 A 172.
3 A 164.
4 A 175.
5 A 171.
6 A 181.
7 A 151.
8 A 165.
9 A 170.
10 A 164.
# ℹ 20 more rows散点图:
ggplot(height_df, aes(x = group, y = height)) +
geom_point()
如果使用stat_summary()会发生什么?
ggplot(height_df, aes(x = group, y = height)) +
stat_summary()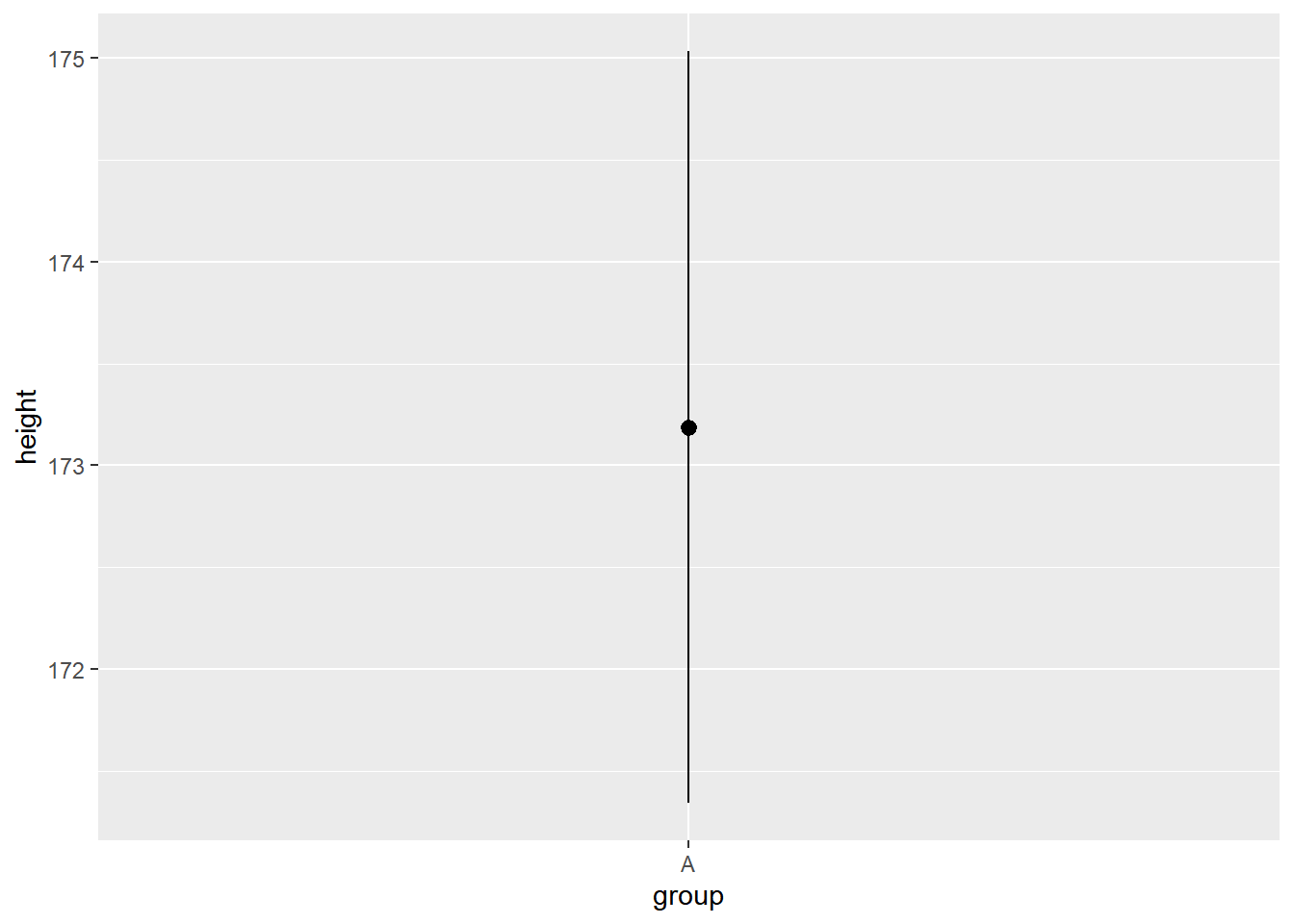
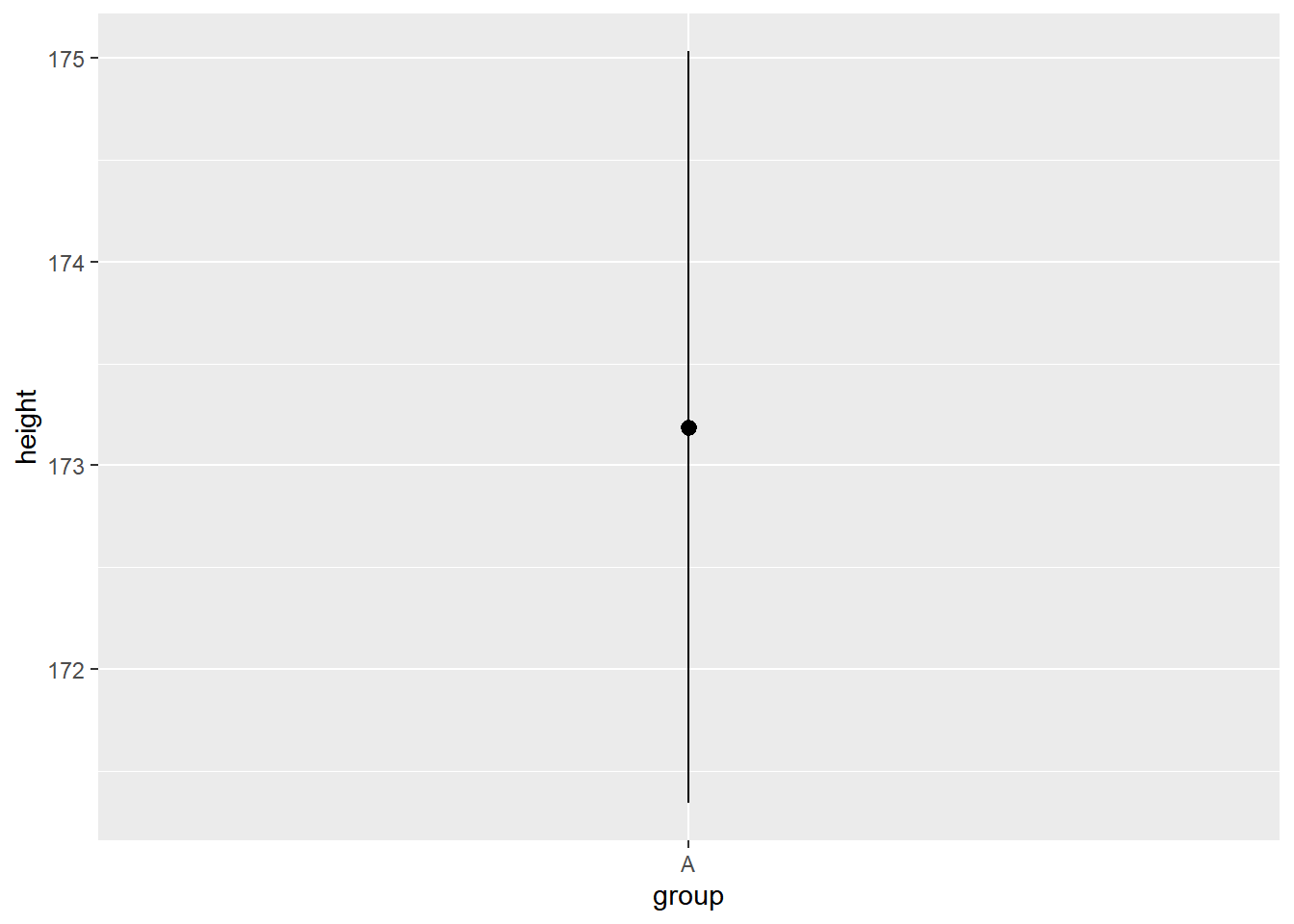
图形变成了一个点和经过它的一条直线?
其实,stat_summary()函数做了以下工作:
函数内如果没有指定数据,则从
ggplot()中继承;参数fun.data 会调用函数将数据变形,这个函数默认是mean_se();
fun.data 返回的是数据框,这个数据框将用于geom参数画图,这里缺省的geom是pointrange;
如果fun.data 返回的数据框包含了所需要的美学映射,图形就会显示出来。
为了更好的理解以上工作,我们把它在代码中显示出来
height_df %>%
ggplot(aes(x = group, y = height)) +
stat_summary(
geom = "pointrange",
fun.data = mean_se
)
4 使用统计图层
那么该如何顺畅的使用stat_summary()呢?
4.1 包含95%置信区间的误差棒
使用企鹅数据画出不同性别下企鹅体重均值的误差棒,同时误差棒要给出95%置信区间(在均值基础上加减1.96倍的标准误)。
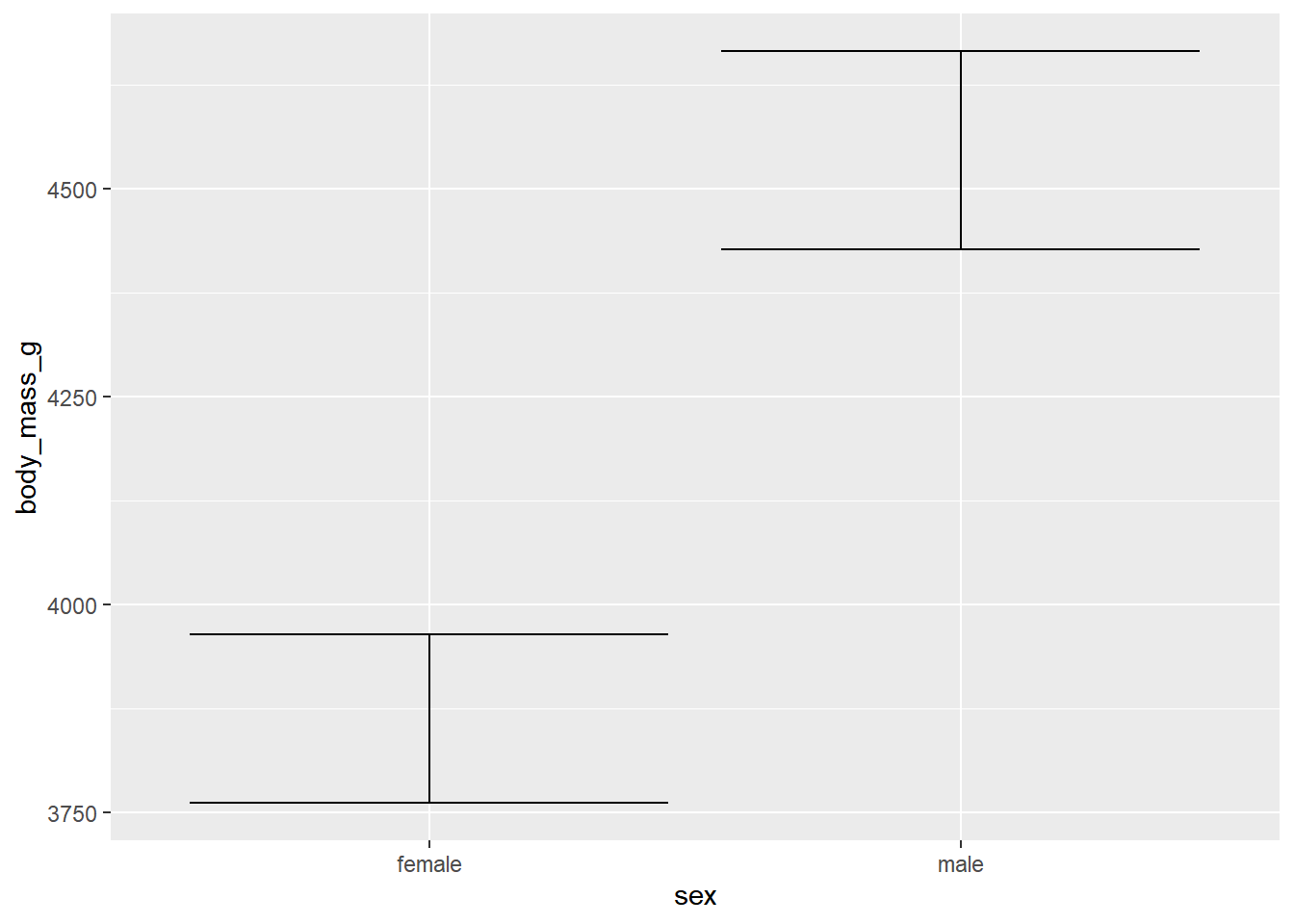
4.2 大小变化的点线图
我们现在想画不同岛屿islands上企鹅bill_depth_mm均值,要求点线图中点的大小随观测数量(该岛屿企鹅的数量)变化
my_df %>%
ggplot(aes(species, bill_depth_mm)) +
stat_summary(
fun.data = function(x) {
scale_size <- length(x) / nrow(my_df)
mean_se(x) %>%
mutate(size = scale_size)
}
)
上图中stat_summary()内部发生了什么?或者说数据是怎么进行转换的?
my_df %>%
group_split(species) %>%
map(~ pull(., bill_depth_mm)) %>%
map_dfr(
function(x) {
scale_size <- length(x) / nrow(my_df)
mean_se(x) %>%
mutate(size = scale_size)
}
) y ymin ymax size
1 18.34726 18.24635 18.44817 0.4384384
2 18.42059 18.28290 18.55828 0.2042042
3 14.99664 14.90625 15.08702 0.35735745 总结
尽管数据是tidy的,但它未必能代表你想展示的值
解决办法不是去规整数据以符合几何形状的要求,而是将原初tidy数据传递给ggplot(), 让stat_*()函数在内部实现变型
可以stat_()函数可以定制geom以及相应的变形函数。当然,定制自己的函数,需要核对stat_()所需要的变量和数据类型
如果想用不同的geom,确保变换函数能计算出(几何形状所需要的)美学映射
那么什么时候用stat,什么时候用geom呢?这不是一个非此即彼的问题,事实上,他们彼此依赖– 我们看到stat_summary() 有 geom 参数, geom_() 也有 stat 参数。 在更高的层级上讲,stat_()和 geom_*() 都只是ggplot里构建图层的layer()函数的一个便利的方法。